Why Hybrid Retrieval Is Becoming a Strong Default Pattern
Retrieval augmented generation has become a common architectural choice for building grounded AI systems. As teams move from experimentation to production, the conversation often shifts from model capability to retrieval reliability.
In that discussion, one statement frequently comes up:
Hybrid retrieval is not optional anymore.
I would frame that differently.
Hybrid retrieval is not a universal rule. It is a perspective shaped by practical experience across complex systems. There are still valid cases where purely sparse or purely dense retrieval works well. However, hybrid retrieval is increasingly emerging as a strong default pattern when systems grow in scale and complexity.
Let us unpack that nuance.
1. Sparse Retrieval Remains Highly Effective in Some Domains
Sparse retrieval methods such as BM25 rely on token overlap and statistical weighting. They perform particularly well when:
- Queries contain exact identifiers, codes, SKUs, policy numbers
- Terminology is standardized and consistent
- Precision outweighs semantic flexibility
- The corpus is structured and curated
In regulatory systems, legal repositories, or structured knowledge bases, keyword retrieval can be both efficient and sufficient.
In such environments, adding dense retrieval may not materially improve outcomes and could introduce unnecessary complexity.
2. Dense Retrieval Alone Can Be Appropriate
Dense retrieval, powered by embeddings, excels when:
- Users ask questions conversationally
- Synonyms and paraphrasing dominate
- Exact phrasing is unpredictable
- The corpus is relatively homogeneous
Customer support assistants and internal knowledge copilots often benefit significantly from semantic search alone. If evaluation metrics show strong recall and precision with embeddings, there may be little incentive to introduce a second retrieval strategy.
So hybrid retrieval is not a mandate. It is a design choice shaped by context.
3. Where Single Strategy Approaches Show Limitations
As systems expand, certain patterns tend to appear:
- Corpora become more diverse, mixing policies, emails, PDFs, transcripts
- Users alternate between precise identifiers and vague intent
- Language style varies across departments
- Edge cases increase
Sparse retrieval may miss semantically relevant passages. Dense retrieval may overlook rare tokens or specific identifiers.
Each method has strengths and blind spots. Whether those blind spots matter depends on the use case, risk tolerance, and performance expectations.
4. Hybrid Retrieval as a Practical Middle Ground
Hybrid retrieval combines sparse and dense signals rather than choosing one exclusively.
A simplified architecture looks like this:
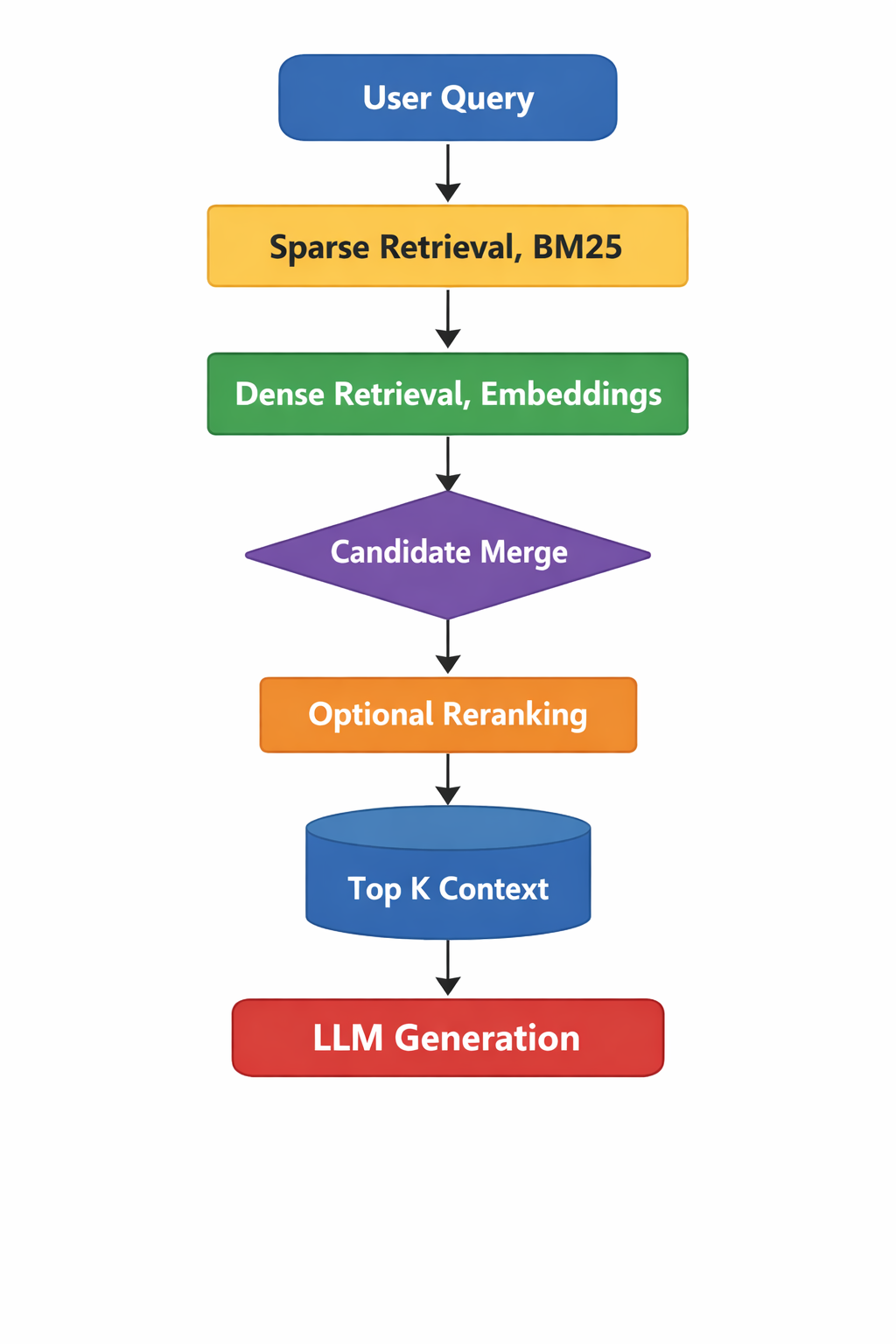
The objective is not redundancy. It is resilience.
When both sparse and dense retrieval surface the same document, confidence increases. When they differ, merging and reranking provide a mechanism to arbitrate relevance.
In many complex deployments, this layered approach improves recall stability across varied query patterns. That observation is based on common industry practice and practical implementation experience, not a mathematically universal conclusion.
5. The Role of Cross Encoder Reranking
After retrieving candidates through sparse and dense methods, ranking quality becomes critical.
Cross encoder reranking evaluates the query and document together, allowing the model to attend across both sequences and assign a more precise relevance score.
This additional step is particularly useful when:
- Candidate sets are large
- Precision at top K is critical
- Hallucination risk must be minimized
- Context window space is limited
However, reranking introduces additional latency and compute cost. In smaller systems or lower risk environments, simpler ranking strategies may be sufficient.
6. Trade Offs and Design Considerations
Hybrid retrieval introduces:
- Additional indexing pipelines
- More parameters to tune
- Slightly increased latency
- Higher operational complexity
Therefore, the decision should be driven by:
- Corpus diversity
- Query variability
- Risk tolerance
- Performance benchmarks
- Infrastructure constraints
In tightly scoped applications, simpler architectures may be more appropriate.
7. Why Hybrid Is Often a Strong Default in Complex Systems
While not universally required, hybrid retrieval often proves beneficial when:
- Data sources are heterogeneous
- Query behavior is unpredictable
- Precision and semantic flexibility both matter
- Governance and grounding are priorities
In such environments, relying on a single retrieval signal can create edge case failures that are difficult to anticipate during early testing.
Hybrid retrieval does not guarantee correctness. It increases the probability that relevant context is surfaced consistently across diverse scenarios.
That makes it a compelling default pattern in many, though not all, production grade AI systems.
Closing Thoughts
Retrieval architecture is a design decision, not a doctrine.
Sparse retrieval remains powerful. Dense retrieval unlocks semantic flexibility. Cross encoder reranking sharpens precision.
Hybrid retrieval reflects a practical synthesis of these strengths. It is not an absolute rule, but in many complex environments, it offers a balanced approach that reduces blind spots and improves robustness.
As AI systems mature, thoughtful retrieval design may matter as much as model selection itself.