Temporal Reasoning in LLMs: Practical Patterns from Emerging Research
A model can sound intelligent and still misunderstand the timeline of events. In production systems, that gap quickly becomes visible.
As LLMs move into finance, healthcare, legal workflows, and operational analytics, temporal reasoning is no longer an academic curiosity. Many enterprise tasks depend not just on what happened, but when it happened, in what order, and under what time constraints.
In this post, I want to clarify what temporal reasoning means in practical terms, how reinforcement learning techniques such as RLHF are being explored to strengthen it, and what engineering realities teams should expect when scaling these ideas.
What Temporal Reasoning Really Involves
Temporal reasoning refers to a model's ability to correctly interpret and manipulate time related relationships expressed in language.
This includes:
- Determining event order
- Understanding relative time expressions such as "two days earlier"
- Comparing durations and intervals
- Tracking state changes across multi turn conversations
- Applying time bound constraints in decisions
A simple example:
"The system was patched after the breach was detected, but before the audit was completed. Did the breach occur before the audit?"
The answer depends entirely on correctly constructing the sequence of events.
In enterprise environments, the complexity grows:
- Financial systems reconcile transactions across reporting periods
- Healthcare records track medication adjustments across visits
- Compliance engines enforce deadlines and effective dates
- Security systems evaluate event frequency within defined time windows
Temporal reasoning errors in these contexts can lead to incorrect outputs even when the language appears coherent.
Why Pretraining Alone Is Insufficient
Large language models are trained primarily using next token prediction. This objective builds strong pattern recognition and linguistic fluency.
Temporal reasoning, however, often requires:
- Maintaining structured internal representations
- Enforcing logical consistency across multiple steps
- Handling long horizon dependencies
While models can learn temporal patterns implicitly, they are not explicitly optimized for strict chronological consistency.
As reasoning chains grow longer, models may:
- Confuse relative references
- Collapse multiple events into simplified narratives
- Produce plausible but temporally inconsistent answers
This gap motivates exploration of reinforcement learning based fine tuning for temporal objectives.
Applying Reinforcement Learning to Temporal Tasks
In current research practice, there is no dedicated "temporal RL framework." Instead, existing alignment pipelines such as Reinforcement Learning from Human Feedback, RLHF, are adapted to emphasize temporal correctness.
A typical training pipeline looks like this:
- Supervised Fine Tuning on instruction and reasoning data
- Collection of human or synthetic preference data focused on temporal validity
- Training a reward model that scores outputs for chronological consistency
- Policy optimization, often using algorithms such as Proximal Policy Optimization, PPO
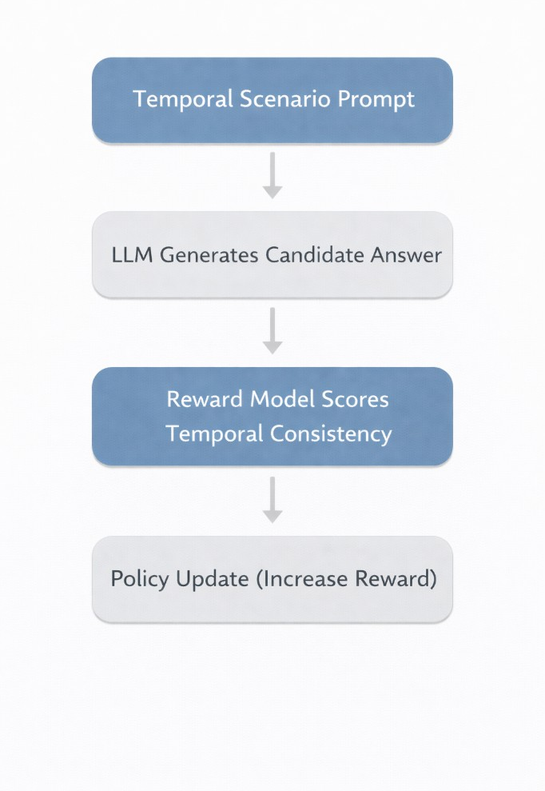
The distinguishing factor is the reward design. Instead of optimizing mainly for helpfulness or safety, the reward explicitly captures:
- Correct event ordering
- Accurate duration calculations
- Logical consistency across intermediate steps
In some experiments, structured intermediate supervision is added. For example:
- Extract events and timestamps
- Normalize relative expressions into absolute forms
- Check constraints using rule based evaluators
Reinforcement learning then encourages the model to produce outputs aligned with these structured validations.
Hybrid Symbolic Neural Patterns
One pattern that appears repeatedly is the benefit of combining neural models with deterministic temporal reasoning modules.
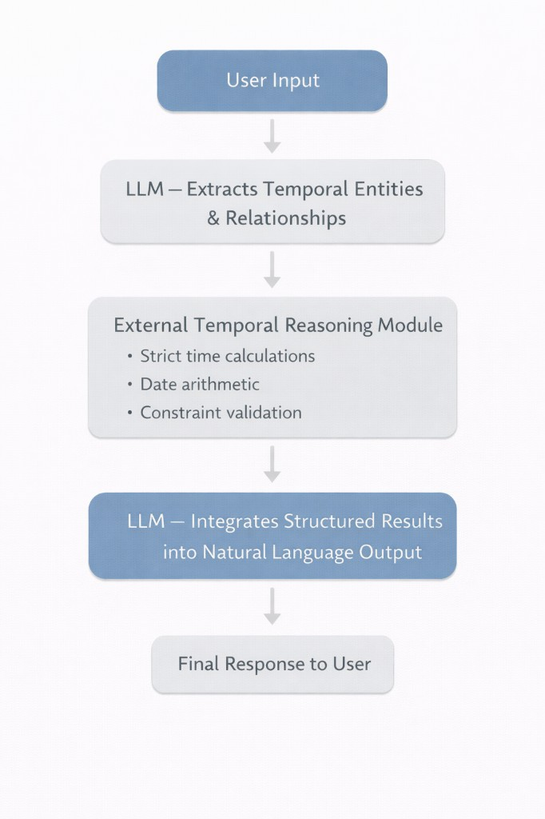
The external module handles tasks such as:
- Date arithmetic
- Interval overlap checks
- Deadline validation
Reinforcement learning can be used to improve:
- Accuracy of temporal extraction
- Appropriate delegation to tools
- Final answer consistency
This hybrid architecture reduces the burden on the LLM to perform exact arithmetic internally.
Engineering Challenges in Production
Reinforcement learning improves targeted capabilities, but scaling RL augmented temporal reasoning systems is non trivial.
Reward Design Complexity
Temporal correctness is subtle. Small labeling inconsistencies can produce noisy reward signals.
Designing high quality temporal datasets requires domain expertise and careful edge case coverage.
Long Horizon Credit Assignment
Temporal reasoning often spans multiple steps. Rewards may only be computed at the end of generation.
Identifying which intermediate decision caused a failure is difficult. Techniques such as stepwise supervision or curriculum learning can help stabilize training.
Compute and Iteration Cost
Policy optimization methods such as PPO require multiple forward passes and careful tuning.
Compared to pure supervised fine tuning, this increases infrastructure demands and experimentation cycles.
Evaluation in Real Workflows
Offline benchmarks are insufficient.
Temporal reasoning must be validated in:
- Multi turn dialogues
- Long context interactions
- Domain specific operational scenarios
Continuous evaluation pipelines are essential to detect regressions.
A Practical Way to Approach Adoption
Before investing in RL based temporal optimization, I typically assess three questions:
- Is temporal correctness mission critical
- Can rule based systems handle the required logic more reliably
- Do we have representative temporal datasets for training and evaluation
If temporal errors create high business risk and deterministic rules are insufficient, reinforcement learning can provide measurable improvements.
If not, a simpler hybrid approach may deliver sufficient reliability at lower cost.
Temporal reasoning forces us to move beyond surface fluency and into structured coherence. As LLM systems become more stateful and integrated into operational workflows, this capability will increasingly define whether a model is merely articulate, or genuinely dependable.