Stop Using One LLM for Everything
Large Language Models have come to the fore as the default building block for AI systems. A new feature request appears, and the first instinct is simple:
"Just call the LLM."
Need summarization? LLM.
Need classification? LLM.
Need retrieval? LLM.
Need validation? LLM.
Need reasoning? Same LLM.
This pattern is understandable. It is fast. It reduces integration effort. It feels powerful.
But it is also becoming one of the most expensive architectural mistakes teams are making.
It is time to stop using one LLM for everything.
1. The Myth of the Universal Model
Modern foundation models are impressive. They can:
- Generate long form text
- Classify sentiment
- Extract entities
- Translate languages
- Write code
- Answer questions
Because they can do all of this, we assume they should.
Capability does not imply optimality.
A general purpose model is trained to do many things reasonably well. It is rarely the most efficient, cheapest, or safest component for a specific task inside a production system.
When we treat a single LLM as the universal engine, we blur the boundary between:
- Core reasoning
- Deterministic processing
- Retrieval
- Business rules
- Validation
This leads to inflated cost, reduced reliability, and architectural fragility.
2. Not All Tasks Are Generative Tasks
Many workflows that teams implement with an LLM are not inherently generative.
Consider a typical enterprise assistant:
User query → Retrieve documents → Filter → Format → Generate response
In many cases:
- Retrieval should be vector search
- Filtering should be deterministic logic
- Formatting should be templated
- Validation should be rule based
Only synthesis may require an LLM.
Yet I often see systems structured like this:
User query → LLM → LLM decides what to retrieve → LLM filters → LLM formats → LLM validates → LLM outputs
This is not architecture. It is delegation.
Here is a simplified comparison:
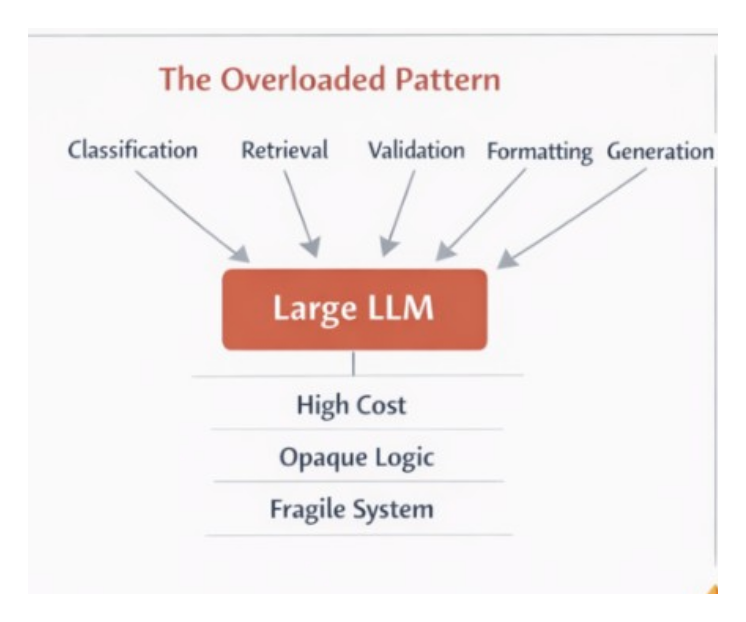
Overloaded Pattern
User → LLM → Everything
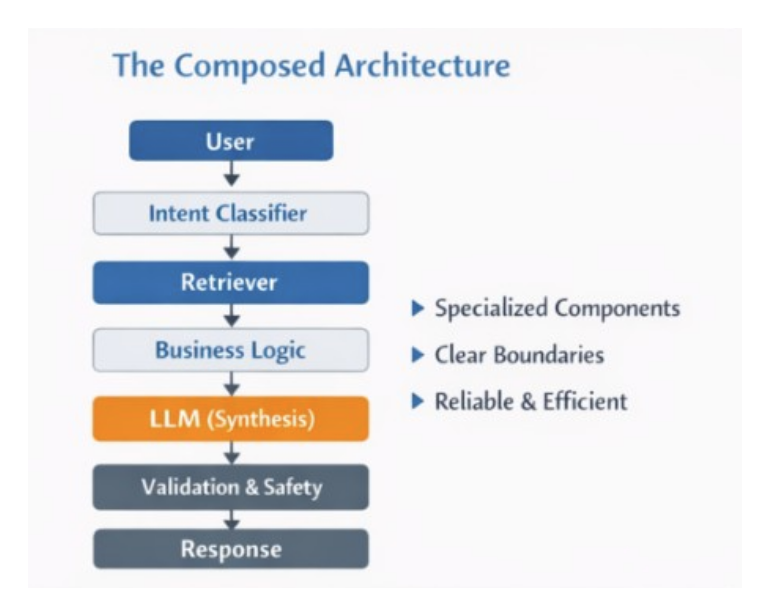
Composed Pattern
User → Retriever → Business Logic → LLM → Validator → ResponseThe second pattern is modular. The first is opaque.
3. Cost Explosion Is Silent
Large models are not cheap. Every token costs money and latency.
If you use a large model for:
- Binary classification
- Keyword extraction
- Schema validation
- Simple routing
You are paying generative pricing for deterministic work.
Multiply that by thousands of daily requests and cost becomes non trivial.
A better approach is tiered modeling:
- Small model for classification
- Embedding model for retrieval
- Rules engine for validation
- Larger model only for synthesis
Architecturally, this looks like specialization rather than centralization.
4. Reliability Improves With Specialization
When one model handles everything, failure modes become coupled.
If the model drifts, everything drifts.
If a prompt changes, downstream behavior changes.
If output format varies, parsing breaks.
Specialized components reduce blast radius.
For example:
- Deterministic JSON schema validation should not depend on a probabilistic model
- Safety filtering can be isolated
- Business rules should not be learned implicitly by a prompt
This separation mirrors established distributed systems design: isolate concerns, constrain variability, reduce hidden coupling.
5. The Right Model for the Right Layer
We have multiple model categories available:
Generative Models
Large instruction tuned models optimized for reasoning and synthesis.
Embedding Models
Efficient vector encoders for retrieval and similarity search.
Smaller Fine Tuned Models
Lightweight classifiers trained for specific domains.
Rule Based Systems
Deterministic and explainable logic engines.
A mature AI system composes these, rather than collapsing them into a single endpoint.
6. A Composed Architecture Pattern
Below is a high level architectural pattern that avoids the single model trap.
Conceptually:
- Input classification layer decides intent
- Retrieval layer gathers context
- Deterministic logic layer applies constraints
- LLM synthesis layer generates output
- Validation layer enforces schema and safety
- Monitoring layer tracks behavior
Each layer has a clear contract.
Each layer can evolve independently.
This is not over engineering. It is system design discipline.
7. When Is One LLM Acceptable?
There are valid scenarios:
- Rapid prototyping
- Low volume internal tools
- Early stage experimentation
- Non critical content generation
In these cases, simplicity wins.
But once a system becomes:
- User facing
- High volume
- Regulated
- Business critical
Single model architecture becomes fragile.
8. The Strategic Shift
The industry conversation has focused heavily on model capability. That is important. But production impact depends on architecture.
We should shift from asking:
"Which LLM should we use?"
To asking:
"What responsibilities should the LLM actually own?"
In well designed systems, the LLM is powerful, but constrained.
It synthesizes.
It does not govern.
It does not validate.
It does not replace deterministic reasoning where determinism is required.
9. Final Thoughts
The temptation to centralize everything into one powerful model is understandable. It feels elegant.
But elegance in AI systems comes from composition, not concentration.
Use large models where probabilistic reasoning adds value.
Use smaller models where classification is sufficient.
Use rules where correctness matters.
Use retrieval where memory is required.
Architect for specialization, not convenience.
That is how we move from impressive demos to durable systems.