Small Models, On Device AI, and Edge Strategy
There is a quiet assumption creeping into many architecture discussions: bigger models are always better. More parameters, larger context windows, frontier APIs with impressive benchmarks.
But in several enterprise deployments, I have seen the opposite pattern emerge.
Not every use case needs a frontier model. In fact, many do not.
As organizations mature in their AI adoption, the conversation is shifting from raw capability to architectural fit. Small models, on device inference, and edge strategies are no longer niche experiments. They are becoming deliberate design choices.
Let us unpack what is driving this shift.
The Overuse of Frontier APIs
Frontier models from providers like OpenAI, Anthropic, and Google DeepMind have pushed reasoning quality to impressive levels. For complex multi step reasoning, coding assistance, and creative generation, these systems are powerful.
However, I am noticing a recurring architectural pattern.
Every workflow, even simple classification or structured extraction tasks, gets routed to a frontier API.
This creates several consequences:
- Higher cost per query
- Increased latency due to network round trips
- Data residency concerns
- Rate limit bottlenecks under load
For many enterprise workloads such as intent classification, entity extraction, summarizing short messages, or policy tagging, the capability envelope of a frontier model is underutilized.
It is similar to using a high performance GPU cluster to render a spreadsheet.
Technically feasible, economically inefficient.
Where Small Models Shine
Smaller models, especially those in the 1B to 8B parameter range, have improved meaningfully through distillation and targeted fine tuning. That said, the degree of improvement depends heavily on task narrowness and domain constraint. They excel when the objective space is well defined, less so when open ended reasoning is required.
Distillation plays a central role here.
A typical pattern looks like this:
- Use a large teacher model to generate high quality outputs or preference data
- Train a smaller student model to mimic that behavior
- Fine tune for domain specific objectives
This creates a capability transfer loop:
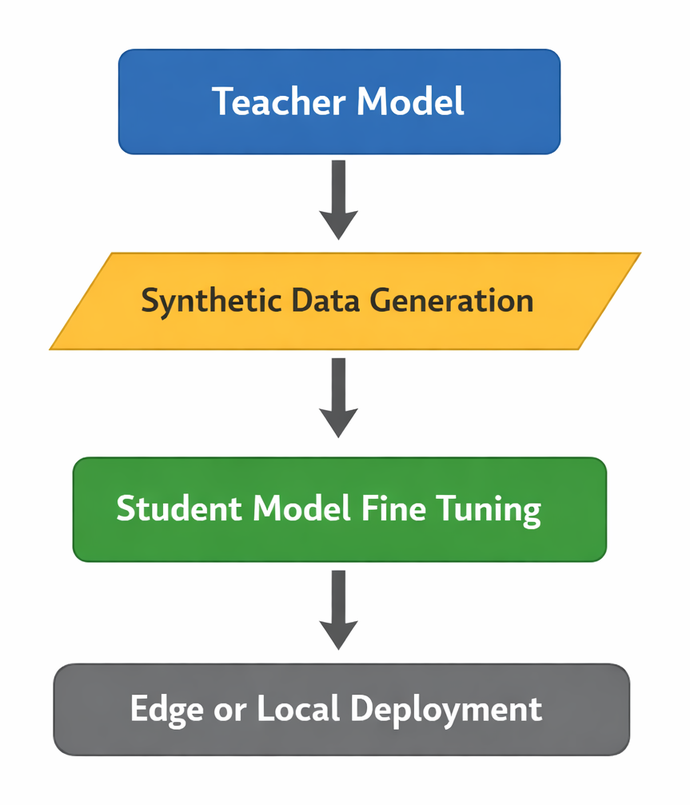
The result is often a compact model that performs extremely well on narrow tasks with clear boundaries.
Where they particularly shine:
- Real time classification under tight latency budgets
- On device summarization for constrained message lengths
- Embedded copilots inside enterprise tools with predictable workflows
- Structured extraction from fixed templates
In these cases, inference time can drop from hundreds of milliseconds over network calls to tens of milliseconds locally.
That latency difference is not cosmetic. It fundamentally changes user experience.
Latency and On Device Advantages
On device inference removes several variables:
- No external API call
- No unpredictable network jitter
- Reduced dependency on centralized rate limits
For mobile and IoT scenarios, this becomes critical.
Consider a field inspection app running in low connectivity environments. Routing every query to the cloud introduces fragility. A small on device model provides resilience.
There is also a cost benefit.
Cloud based frontier models charge per token. Edge deployed models amortize compute cost across devices. When scaled to millions of interactions, that shift materially impacts total cost of ownership.
From a systems perspective, local inference can reduce peak backend inference load for common paths. However, it does not eliminate backend infrastructure needs entirely. Telemetry, model updates, policy checks, and fallback routing still require cloud coordination.
Instead of the traditional cloud path:
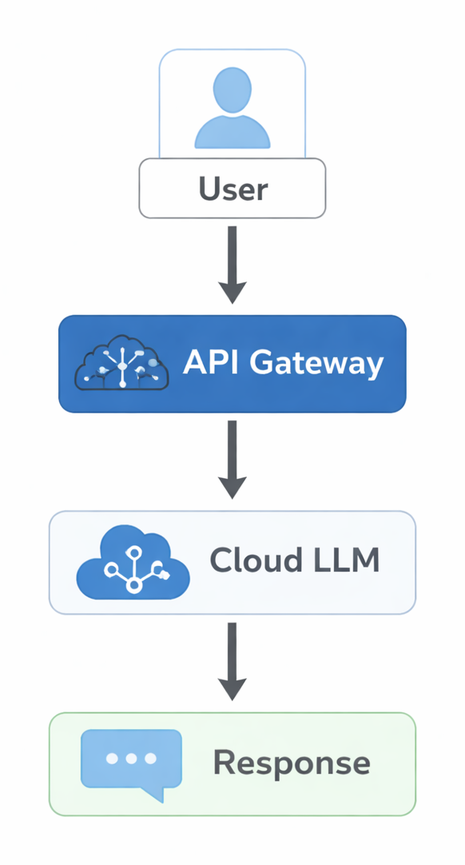
You may get a lighter on device path:
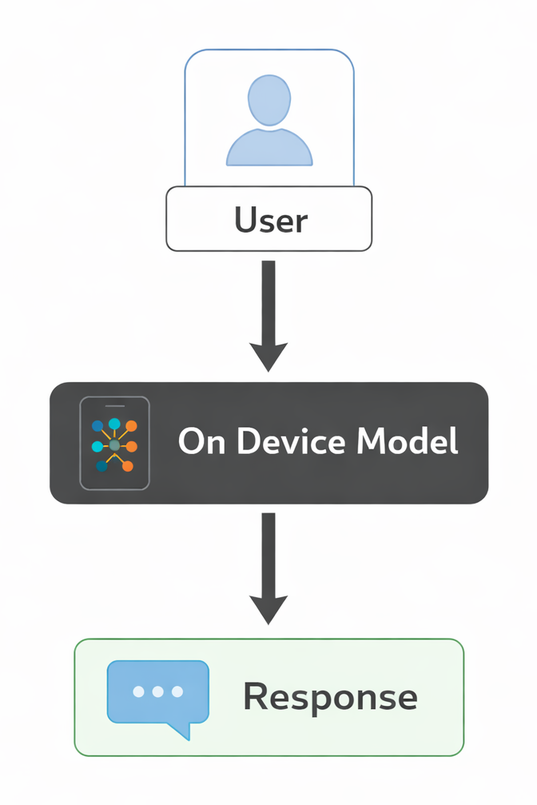
A hybrid pattern adds confidence based escalation: the on device model handles high confidence cases locally, while uncertain requests escalate to the cloud LLM.
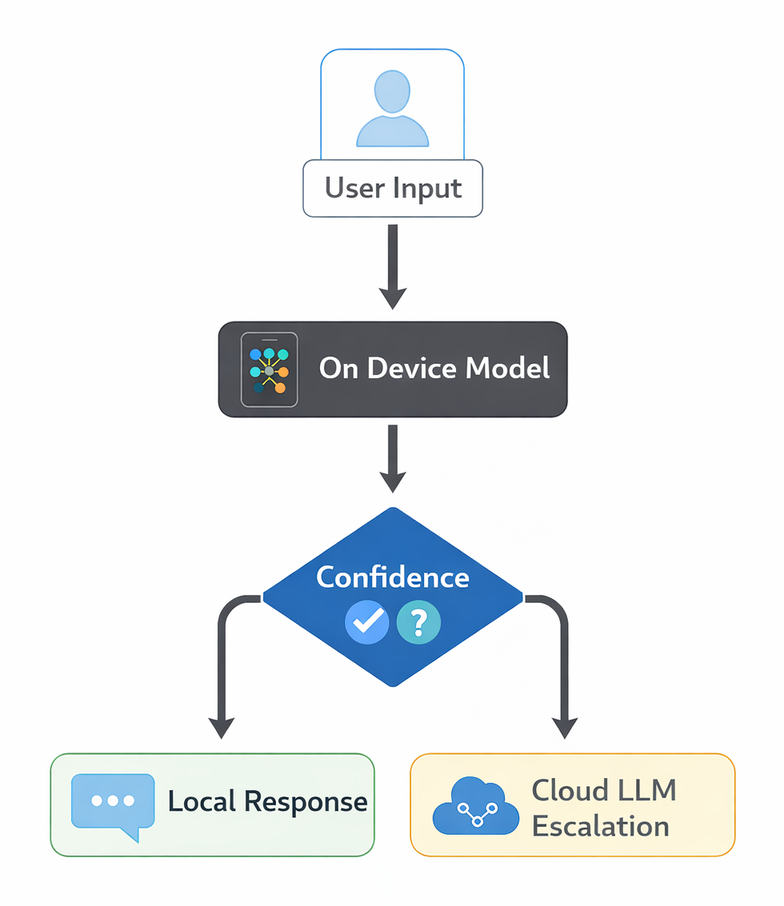
The architecture becomes lighter for inference, but not infrastructure free.
Privacy and Regulatory Benefits
Privacy concerns are no longer theoretical. Regulatory frameworks around data residency and processing are tightening across regions.
Keeping inference local reduces:
- Transmission of sensitive data
- Cross border data flow complexity
- Audit surface for external vendors
For healthcare, finance, and public sector use cases, on device or on premise inference can simplify compliance reviews.
This does not eliminate risk. Model artifacts must still be secured, updates must be controlled, and logging policies must be designed carefully.
But the exposure model changes. Instead of transmitting raw prompts externally by default, sensitive data can remain within controlled device or enterprise boundaries.
Edge Deployment Constraints
Edge strategy is not a free upgrade.
Constraints are real:
- Limited RAM on devices
- Battery consumption concerns
- Thermal constraints
- Model update logistics
Quantization becomes essential. Moving from FP16 to INT8 or lower precision formats can dramatically reduce memory footprint.
Pruning and structured sparsity techniques also help compress models further.
However, aggressive compression can degrade quality. The trade off between footprint and accuracy must be evaluated carefully per task.
Another overlooked factor is maintenance overhead.
Cloud APIs abstract away model lifecycle management. With on device deployments, you now own:
- Version control
- Rollout strategies
- Backward compatibility
- Telemetry collection
- Secure model artifact distribution
Updating a model across millions of distributed devices is operationally non trivial.
A Practical Evaluation Framework
When deciding between frontier APIs and small on device models, I find it helpful to evaluate along five dimensions:
- Task boundedness: Is the problem narrow enough for distilled capability
- Latency tolerance: Can the workflow absorb network round trips
- Data sensitivity: Does the data justify local inference
- Cost profile: What is projected cost at scale
- Operational ownership: Does the team have capacity to manage distributed model lifecycles
Small models are not universal replacements for frontier systems. Frontier systems are not necessary for every workflow.
Edge strategy is an architectural choice, not a marketing narrative.
If we approach it as a portfolio decision rather than a binary choice, the design space becomes clearer. That mindset, in my experience, leads to more resilient and economically sound AI systems.