Scaling RAG Architectures: From Experiment to Production
There is a noticeable shift that happens when Retrieval Augmented Generation moves from a proof of concept to a production system. In early demos, retrieval feels magical. The model answers questions grounded in your documents, hallucinations drop, stakeholders are impressed.
Then scale arrives.
Latency spikes, index refresh becomes a debate, semantic mismatches surface, and teams realize retrieval is not just an add on, it is a distributed systems problem.
Across multiple technical discussions recently, one pattern keeps emerging. RAG success at scale depends less on the model and more on retrieval architecture discipline.
Let me walk through how I am thinking about RAG patterns in large systems, where they break, and what tends to work.
Revisiting the Core Retrieval Patterns
At its core, RAG combines two systems:
- A retriever that selects relevant context
- A generator that synthesizes an answer
The quality of that first step determines everything downstream.
Dense Retrieval
Dense retrieval uses embeddings to represent documents and queries in vector space. Semantic similarity drives recall.
Strengths:
- Handles paraphrasing well
- Captures conceptual similarity
- Works across heterogeneous document structures
Constraints:
- Sensitive to embedding drift
- Harder to debug compared to keyword search
- May retrieve semantically similar but policy irrelevant documents
In enterprise deployments, dense retrieval alone often performs well for exploratory search and summarization tasks. However, for high precision use cases such as regulatory QA or contractual clauses, semantic similarity is not always enough.
Sparse and Hybrid Retrieval
Traditional keyword search still has a role.
Sparse methods such as BM25 remain highly precise when exact terminology matters. In many production systems, I am seeing hybrid retrieval patterns:
- Sparse retrieval narrows candidate set
- Dense retrieval reranks semantically
- Cross encoder optionally refines top results
Hybrid pipelines introduce complexity but significantly improve precision recall balance in enterprise knowledge bases.
Vector Store Choices at Scale
Vector databases look interchangeable during early experimentation. At scale, they are not.
Design considerations include:
- Indexing strategy, HNSW vs IVF
- Memory footprint vs disk based retrieval
- Sharding and replication model
- Consistency guarantees during updates
- Support for metadata filtering
In production, the question shifts from "Which vector DB is fastest?" to "Which indexing model supports our update frequency and tenancy model?"
Multi tenant enterprise environments often require:
- Logical isolation of embeddings
- Access control filtering at retrieval time
- Audit logging of query context
These are rarely first class concerns during experimentation, but they dominate production design reviews.
Where Systems Start Slowing Down
Several bottlenecks appear repeatedly in scaling discussions.
Latency Compounding
RAG latency is cumulative: query embedding, vector search, optional reranking, context assembly, and LLM generation. Each stage may look acceptable individually. Together, they exceed user tolerance.
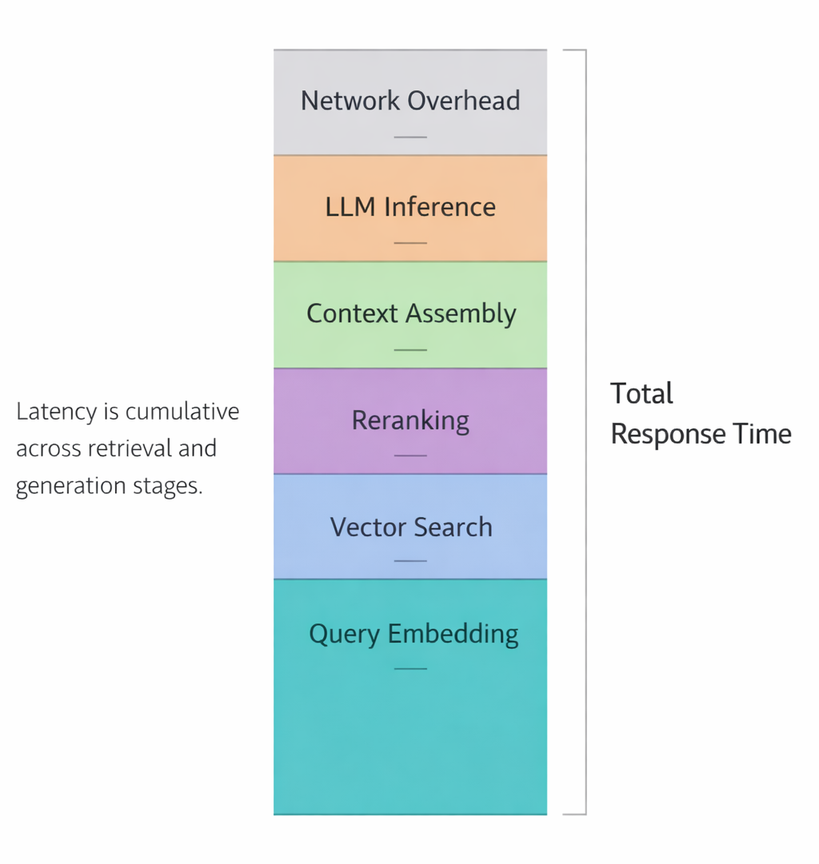
Caching strategies become essential:
- Query embedding caching
- Frequent query result caching
- Precomputed document summaries
- Hierarchical retrieval to reduce token count
When designing RAG systems, I increasingly recommend setting a hard latency budget first, then allocating time per stage. This reverses the typical approach where architecture is decided before performance targets.
Index Update Challenges
Static corpora are rare in enterprises.
Policies update. Product documentation evolves. Knowledge bases grow daily.
Index update questions include:
- Real time vs batch embedding refresh
- Incremental indexing vs full rebuild
- Versioned embeddings for auditability
In discussions with teams managing high change velocity domains, near real time embedding pipelines introduce new failure modes:
- Partial index states
- Embedding inconsistency across shards
- Retrieval returning outdated policy text
A versioned index approach, where each index snapshot is immutable and queries target a specific version, often improves traceability at the cost of storage overhead.
Semantic Drift
Semantic drift occurs when:
- Domain terminology evolves
- Embedding models are upgraded
- Internal taxonomies change
Suddenly, retrieval quality drops without obvious failure signals.
To mitigate this, I am seeing stronger evaluation loops:
- Periodic retrieval recall benchmarks
- Domain specific query test sets
- Drift monitoring based on embedding distribution shifts
RAG systems require observability beyond LLM output metrics. Retrieval itself needs independent evaluation.
Safely Integrating Domain Knowledge
Enterprise RAG is not just about finding relevant content. It must respect boundaries.
Best practices emerging in practice:
- Strict metadata filtering before vector similarity
- Tenant aware index partitioning
- Prompt templates that clearly attribute sources
- Structured answer formats to reduce generative overreach
For sensitive domains such as finance or healthcare, retrieval constraints must precede generation. If the retriever leaks context, the generator cannot fix it later.
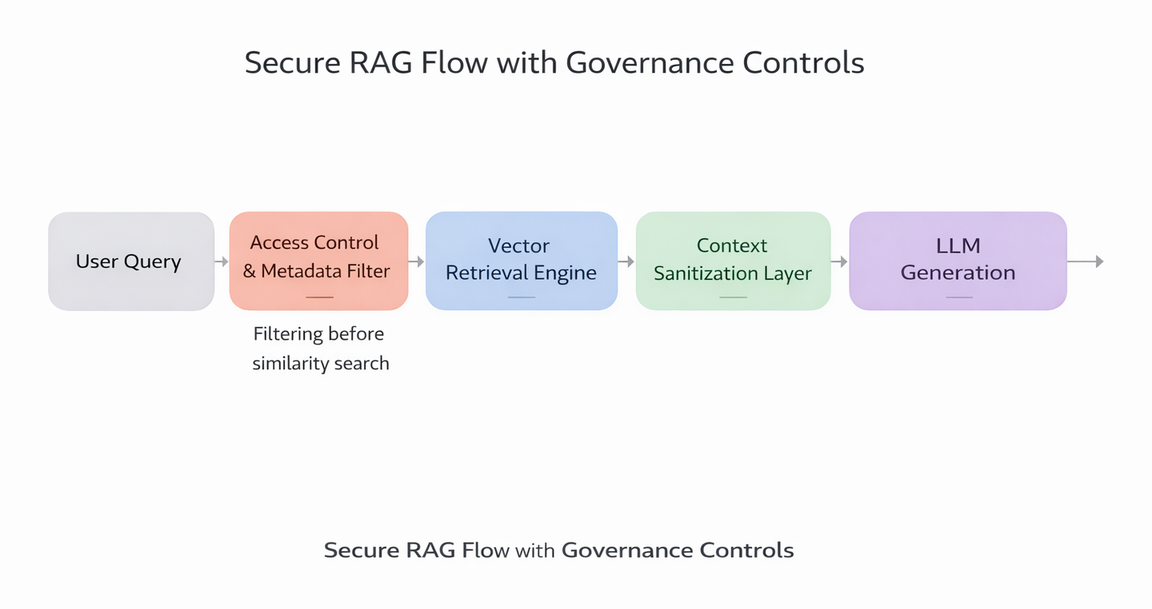
I often recommend separating retrieval service and generation service as independently governed components. This allows retrieval policies to evolve without retraining the model.
Enterprise Use Cases in Practice
From ongoing architecture reviews, several stable RAG patterns are emerging.
Enterprise Search Assistants
Internal search copilots that:
- Retrieve policy documents
- Summarize internal wiki content
- Answer compliance queries with citations
Hybrid retrieval tends to outperform pure dense approaches here.
Customer Support Knowledge Systems
Support agents querying dynamic knowledge bases:
- Product troubleshooting guides
- Release notes
- Escalation procedures
Latency constraints are tighter, so caching and top K reduction strategies matter more.
Long Document Summarization
RAG helps break large documents into chunks, retrieve relevant sections, and generate structured summaries.
Here, chunking strategy becomes critical:
- Overlapping chunks reduce boundary loss
- Smaller chunks improve precision
- Larger chunks reduce retrieval calls
There is no universal rule. Chunking must align with document structure.
A Production Readiness Checklist
When I evaluate whether a RAG system is ready for scale, I tend to walk through this checklist:
- Defined latency budget per stage
- Retrieval quality benchmark with domain test queries
- Index update strategy documented and versioned
- Embedding model upgrade plan
- Access control enforced before similarity search
- Caching layer with eviction policy
- Observability on retrieval recall and drift
RAG is not a single technique. It is an ecosystem of retrieval engineering, indexing strategy, performance budgeting, and governance controls.
As more enterprises rely on RAG for critical workflows, the differentiator will not be who has the largest context window. It will be who treats retrieval as infrastructure.
Scaling RAG is less about adding more documents and more about designing disciplined retrieval systems that remain stable under growth, change, and scrutiny.