RLHF Beyond OpenAI: Can Enterprises Do It Themselves?
Reinforcement Learning from Human Feedback (RLHF) has become one of the most influential techniques shaping modern large language models. Much of the attention has focused on organizations like OpenAI, but enterprises across industries are asking a critical architectural question:
Can we build RLHF systems ourselves?
The answer is yes, but it is neither trivial nor inexpensive. RLHF is not just a training trick. It is an operational system combining compute, human processes, retraining infrastructure, and governance discipline.
Let's break this down systematically.
1. Understanding the RLHF System
At a high level, RLHF consists of:
User Prompts
↓
Model Outputs
↓
Human Preference Ranking
↓
Reward Model Training
↓
Policy Optimization (PPO or similar)
↓
Updated Model
↓
RepeatThis loop continuously adjusts model behavior based on structured human judgment.
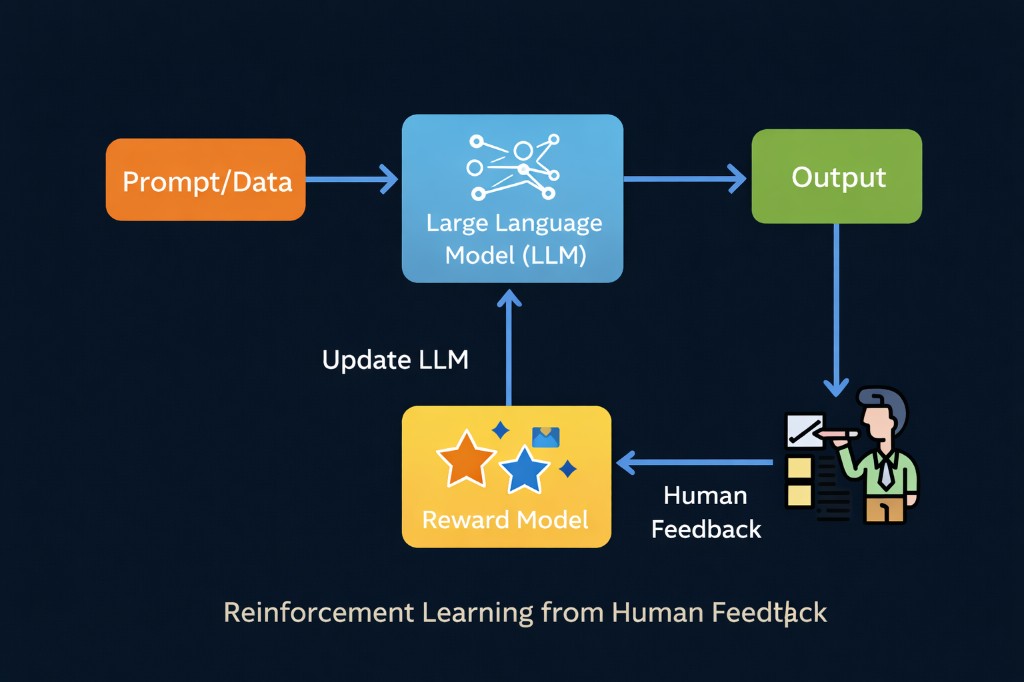
Unlike static supervised fine-tuning, RLHF is inherently iterative and behavioral.
That has implications for cost, infrastructure, and governance.
2. Cost: The Structural Barrier
2.1 Compute Cost
Training frontier-scale models from scratch remains out of reach for most enterprises. However, running RLHF on top of open base models is technically feasible.
Cost drivers include:
- GPU clusters for reward model training
- GPU time for policy optimization cycles
- Experimentation runs and hyperparameter sweeps
- Storage for model checkpoints and datasets
RLHF requires multiple training stages. Each stage compounds compute usage.
Organizations without established GPU infrastructure will face high initial capital or cloud costs.
2.2 Human Annotation Cost
RLHF is fundamentally human-driven.
You need:
- Pairwise preference comparison tasks
- Policy compliance labeling
- Domain-specific quality scoring
- Ongoing annotation audits
Annotation is not a one-time setup.
It becomes a continuous operational function.
The cost scales with:
- Dataset size
- Domain complexity
- Desired alignment precision
Low-quality annotation directly degrades reward model reliability.
High-quality annotation requires process design, training, and quality control.
3. Annotation Pipelines: Building the Human Feedback Engine
Enterprises attempting RLHF must build structured annotation systems.
3.1 Data Collection Infrastructure
- Prompt logging systems
- PII redaction layers
- Sampling strategies to capture failure cases
- Versioned dataset storage
3.2 Annotation Interfaces
- Pairwise comparison tools
- Scoring frameworks
- Safety and policy tagging workflows
3.3 Quality Control
- Inter-annotator agreement tracking
- Gold dataset validation
- Drift detection in labeling behavior
This effectively creates a data operations layer.
Without disciplined data engineering, RLHF becomes unstable and inconsistent.
4. Model Retraining Cycles: The Continuous Loop
RLHF introduces an ongoing retraining rhythm:
Deploy → Collect Feedback → Curate Data → Retrain Reward Model
→ Optimize Policy → Evaluate → RedeployThis changes how enterprises think about releases.
You are not shipping deterministic code. You are updating probabilistic behavior.
This requires:
- Behavioral regression testing
- Versioned evaluation benchmarks
- Safety performance thresholds
- Model rollback strategies
Retraining cycles must be deliberate, measured, and documented.
Uncontrolled loops introduce unpredictable behavior shifts.
5. Governance Overhead: The Multiplier Effect
RLHF explicitly shapes model outputs.
That amplifies governance responsibility.
Enterprises must answer:
- Who defines acceptable outputs?
- How are reward models audited?
- How are alignment policies versioned?
- What is the escalation path for harmful responses?
RLHF without governance introduces legal and reputational risk.
Responsible AI practices must be integrated into the loop.
Governance overhead often becomes the hidden cost multiplier in RLHF systems.
6. When Does Enterprise RLHF Make Sense?
RLHF may be justified when:
- Domain-specific behavior alignment is critical
- Regulatory requirements demand tight control
- The organization already operates ML infrastructure
- Long-term model ownership is strategic
It may not be justified when:
- Use cases are generic
- API-based models already perform sufficiently
- Infrastructure maturity is low
- Governance processes are undefined
In many enterprise settings, structured evaluation, prompt engineering, and supervised fine-tuning deliver substantial value with lower operational complexity.
7. A Practical Enterprise Path
A staged approach is more realistic:
- Begin with API-based LLMs
- Build evaluation and monitoring frameworks
- Introduce structured human feedback collection
- Experiment with supervised fine-tuning
- Incrementally incorporate reward modeling components
Full in-house RLHF should be a strategic decision supported by budget, governance, and technical maturity.
Final Thoughts
RLHF is not just an algorithm.
It is an operational commitment combining:
- Compute investment
- Continuous human-in-the-loop processes
- Structured retraining cycles
- Formal governance frameworks
Enterprises can build RLHF systems.
But success depends less on technical feasibility and more on sustained organizational discipline.
The real differentiator is not who experiments with RLHF; it is who can operate it responsibly and sustainably.