RAG with LangChain at Scale: Retrieval Discipline Over Prompt Tricks
There is a moment every team hits with Retrieval Augmented Generation. The demo works beautifully, stakeholders are impressed, and someone says, "Great, we just need to plug in a vector store and we are production ready."
That assumption does not survive scale.
Across multiple architecture discussions this year, I have noticed a clear evolution. RAG is no longer treated as a prompt engineering pattern. It is now treated as retrieval infrastructure. And frameworks like LangChain are increasingly used not as magic abstractions, but as orchestration layers over disciplined retrieval systems.
Let me unpack what changed, what mistakes first generation RAG systems made, and how I am seeing mature teams engineer retrieval as a first class system component.
First Generation RAG Mistakes
Early RAG implementations typically followed a simple recipe:
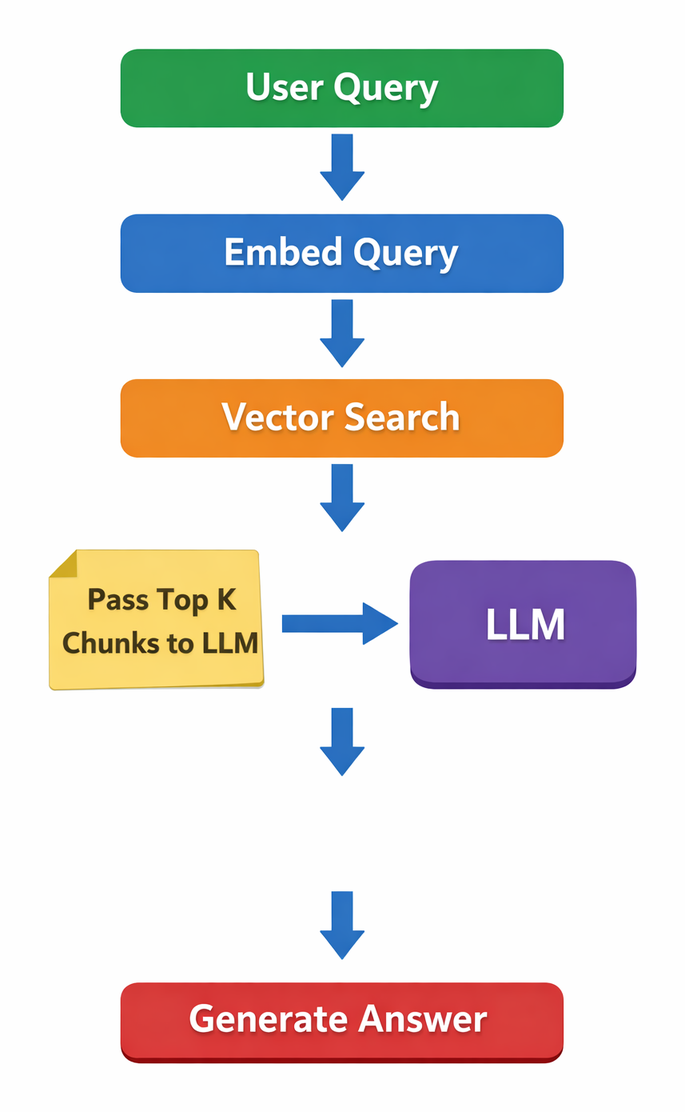
It worked surprisingly well for internal knowledge bases and FAQ style use cases.
But at scale, several cracks appeared.
1. Overreliance on Dense Retrieval
Pure embedding similarity struggles with:
- Short keyword heavy queries
- Numeric filters and structured constraints
- Compliance driven filtering requirements
Teams discovered that semantic similarity alone cannot replace lexical precision.
2. No Reranking Layer
Top K from a vector database is rarely optimal. Without reranking, irrelevant but semantically adjacent chunks pollute context windows.
3. Silent Embedding Upgrades
Upgrading embedding models without reindexing led to subtle semantic degradation. Retrieval quality drifted slowly, dashboards showed no obvious failure, yet answer accuracy declined.
4. Prompt Heavy Hallucination Fixes
Many systems attempted to "fix" hallucinations with prompt constraints alone:
"If the answer is not found in context, say insufficient information."
This helps, but without retrieval discipline, the model may still overinterpret weak context.
These early lessons pushed teams toward retrieval first thinking.
Retrieval First Architecture with LangChain
LangChain has become a useful orchestration layer, especially for chaining retrievers, rerankers, and post processors. But the framework itself does not guarantee retrieval quality. The discipline comes from system design.
A production grade RAG stack now looks closer to this:
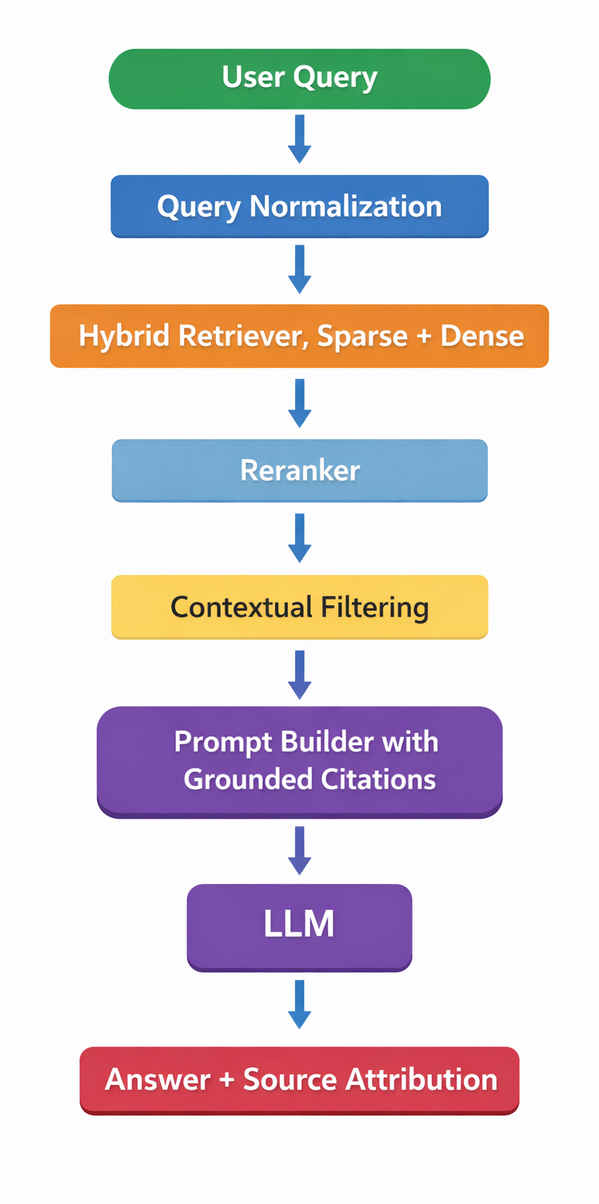
Let us go deeper into the components that matter.
Hybrid Retrieval, Sparse + Dense
Hybrid retrieval combines:
- Sparse retrieval, BM25 or keyword based
- Dense retrieval, embedding similarity
In practice, this improves robustness across query types, especially in enterprise corpora where terminology is domain specific.
A common strategy is weighted fusion:
final_score = alpha * dense_score + beta * sparse_scoreThe weights are tuned empirically per corpus. In LangChain, this is typically implemented via retriever composition and score aggregation before passing to downstream components.
The key shift is this, retrieval is tuned like a ranking system, not treated as a black box.
Rerankers and Contextual Filtering
Even hybrid retrieval produces noise.
A reranker, often cross encoder based, re evaluates the top N results with deeper semantic matching. This adds latency, but significantly improves context precision.
After reranking, contextual filtering applies:
- Document level access control
- Temporal validity filters
- Metadata based constraints
Filtering must happen before final prompt construction. Governance is enforced at retrieval time, not at generation time.
Versioned Vector Indexes
One of the most underappreciated enterprise requirements is traceability.
A robust pattern looks like this:

Older indexes remain immutable. Queries are routed only to the active version.
This allows:
- Controlled embedding upgrades
- Rollback in case of retrieval regression
- Auditability for past responses
LangChain based systems typically externalize this logic to infrastructure layers rather than embedding it directly in chain definitions.
Embedding Drift Monitoring
Embedding models change. So does corpus distribution.
Monitoring must include:
- Retrieval hit rate on validation sets
- Average similarity score trends
- Distribution shifts in embedding vectors
A practical approach is maintaining a golden query set. Every index rebuild runs evaluation against this set. Sudden drops signal drift.
Embedding drift is rarely catastrophic. It is gradual. Without measurement, teams discover it only through user complaints.
Prompt Grounding and Citation Enforcement
Prompt patterns evolved significantly.
Instead of:
"Answer the question using the context."
More disciplined systems enforce:
- Explicit citation markers tied to document IDs
- Structured answer templates
- Refusal behavior when confidence thresholds are low
For example:
You must answer only using the provided context.
For each factual claim, include citation in format [DocID].
If context is insufficient, respond with "Insufficient information."Citation enforcement is not foolproof, but when combined with retrieval quality control, it meaningfully improves transparency.
Governance and Traceability
Enterprise RAG is as much about audit trails as it is about accuracy.
A production trace should log:
- Query text
- Embedding model version
- Index version
- Top K retrieved document IDs
- Reranker version
- Final prompt
- Model version
- Final response
This enables reproducibility and compliance audits.
Without this, debugging becomes guesswork.
Evaluation Metrics Beyond Recall at K
Recall at K is useful but insufficient.
Mature evaluation strategies include:
- Answer faithfulness scoring
- Citation correctness rate
- Retrieval precision at K
- Human graded relevance checks
- Task specific KPIs tied to business outcomes
In several reviews I participated in, teams initially optimized recall aggressively, only to discover that excessive recall hurt generation quality by polluting context.
Balance matters.
Enterprise Hardening Strategies
By the time RAG reaches production scale, teams typically implement:
- Strict access control filtering before similarity search
- Immutable index snapshots
- Automated regression evaluation on every reindex
- Latency budgeting for rerankers
- Fallback strategies when retrieval confidence is low
LangChain plays a valuable role here as orchestration glue. But the durability comes from disciplined retrieval engineering, not clever prompt templates.
A Practical Trade Off Summary
When scaling RAG systems, every design decision involves trade offs:
Hybrid retrieval improves robustness, but adds complexity. Rerankers improve precision, but increase latency. Versioned indexes improve traceability, but consume storage. Strict citation enforcement improves transparency, but may reduce answer fluency.
The shift I have observed is encouraging. Teams are moving from prompt centric experimentation to retrieval centric engineering. RAG is no longer treated as a quick augmentation trick. It is treated as infrastructure.
And in enterprise systems, infrastructure discipline always outperforms prompt tricks.