Retrieval-Augmented Generation at Scale: Patterns, Pitfalls & Enterprise Applications
RAG is often introduced as a reliability upgrade. In practice, it is a systems design decision.
In multiple architecture conversations this year, I have noticed a recurring assumption during early prototypes. Once retrieval is connected to a language model, teams expect factual grounding to improve automatically. And in many cases, it does improve. But that improvement is conditional, not absolute.
Research and production experience both show that Retrieval Augmented Generation can mitigate hallucinations when implemented carefully. It does not eliminate them by default. The difference lies in engineering rigor.
Let me unpack how I am thinking about RAG at scale today, what patterns are working well, and where operational complexity tends to surface.
1. Practical RAG System Design Patterns
At enterprise scale, RAG is a multi stage pipeline. The generator is only one component.
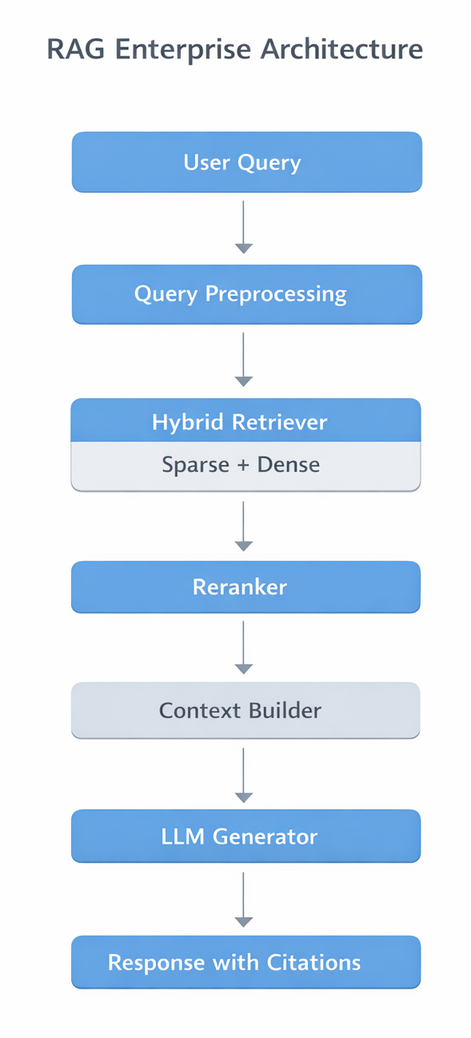
Vector Database Choices
Vector database selection is primarily about workload profile rather than feature comparison.
Teams frequently evaluate platforms such as:
- Pinecone
- Weaviate
- Milvus
- Elastic with hybrid search
Key dimensions I typically examine:
Index structure
- HNSW vs IVF based trade offs between recall, memory, and speed
- Real time updates vs batch indexing
Latency profile
- Median vs tail latency under concurrent load
- Cross region replication cost
Hybrid retrieval capability
- Native BM25 plus embedding fusion
- Metadata filtering performance
There is no universal best choice. For compliance heavy workloads, auditability and tenancy isolation may outweigh pure throughput metrics.
Chunking Strategies
Chunking is one of the most under appreciated variables in RAG design.
Common strategies include:
- Fixed token windows
- Section aware segmentation
- Hierarchical chunking with parent references
In one deployment discussion, moving from naive fixed windows to document structure aware chunking materially improved retrieval precision without increasing embedding volume.
Chunking influences:
- Retrieval recall
- Context redundancy
- Token budget pressure on the generator
Poor chunking does not just reduce relevance. It increases ambiguity, which can expand the model's freedom to speculate.
Latency vs Accuracy Trade Offs
Retrieval depth introduces a direct cost quality trade off.
Top 3 retrieval may reduce latency but risks missing long tail evidence. Increasing k improves recall but increases prompt length and generation latency.
In practice, different enterprises optimize differently:
- Compliance review workflows may prioritize higher recall with reranking layers
- Real time chat assistants may optimize for predictable latency ceilings
There is no single optimal k value. It should be validated against domain specific benchmarks and operational constraints.
2. Specialized RAG Frameworks and Enterprise Platforms in 2025
This year has seen more opinionated RAG tooling from data and AI platforms.
Enterprise platforms from vendors such as:
- Databricks
- Snowflake
- OpenAI
now bundle:
- Managed embedding pipelines
- Integrated vector search
- Hybrid retrieval options
- Built in evaluation tooling
One positive trend is that retrieval observability is becoming more visible. Rather than treating retrieval as a black box, teams are exposing:
- Retrieval hit distribution
- Document citation rates
- Token usage breakdown
That visibility encourages more disciplined iteration.
3. Hallucination Mitigation and Relevance Ranking
RAG reduces hallucination risk when grounding is strong and prompts are carefully structured. It does not guarantee elimination of incorrect outputs.
Irrelevant but Semantically Similar Retrieval
Embedding similarity can retrieve topically related but factually misaligned content.
Mitigations commonly used include:
- Cross encoder reranking
- Hybrid retrieval fusion
- Domain constrained filtering
These improve relevance probabilistically. They do not create certainty.
Generator Ignoring Context
It is well documented that language models may blend retrieved content with parametric knowledge depending on prompt framing and alignment characteristics.
A grounding pattern that is frequently used in practice looks like this:
Answer using only the provided documents.
If the answer cannot be found, state that the information is not available in the documents.
Cite the document identifier.This pattern often improves citation fidelity. It is not foolproof. Different models and domains respond differently, and evaluation is essential.
Stale or Incomplete Indexes
Fast moving enterprises update policies and documentation continuously. If ingestion pipelines lag, retrieval quality silently degrades.
Index freshness monitoring is therefore as important as generator version upgrades.
4. Monitoring RAG in Production
Metrics such as precision, recall at k, and citation rate are commonly used in retrieval evaluation. However, enterprises often complement these with:
- Human review loops
- Domain specific KPIs
- Task success rates
- Escalation frequency
There is no universal metric suite. Monitoring should align with business objectives.
A traceable RAG request ideally logs:
- Query embedding identifier
- Retrieved document IDs
- Prompt template version
- Generator model version
- Final output
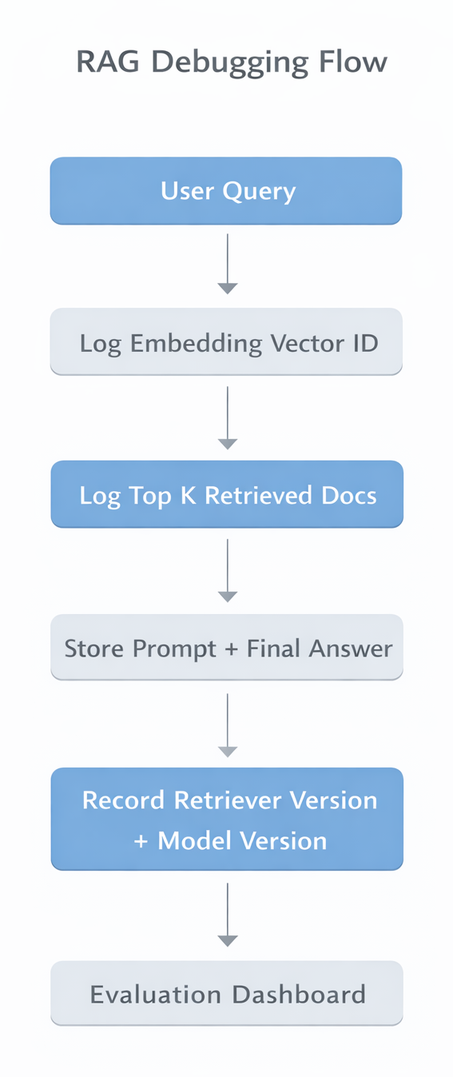
This enables layer specific debugging rather than anecdotal troubleshooting.
5. Debugging RAG Pipelines
When investigating incorrect outputs, isolating components is critical.
Step 1, Retriever Evaluation: Test retrieval independently. Confirm whether the relevant document appears within top k under realistic query phrasing.
Step 2, Context Construction Validation: Check for truncation, ordering artifacts, and metadata leakage.
Step 3, Generator Assessment: Swap generator models while holding retrieval constant. This helps determine whether the issue stems from grounding weakness or model behavior.
6. Versioning Retrievers and Generators
RAG systems have multiple independently evolving components:
- Embedding model
- Chunking logic
- Index configuration
- Reranker
- Generator model
Upgrading an embedding model without reindexing can degrade similarity matching. Updating chunking without re evaluation can alter retrieval distribution.
Treat retriever configuration as versioned infrastructure. Evaluate generator upgrades against a stable retrieval benchmark to avoid conflating variables.
A Trade Off Summary for Enterprise Teams
Before expanding context windows or upgrading to a larger generator, I now walk through a simple checklist:
- Are relevant documents consistently retrieved under realistic queries
- Is chunking aligned with document structure
- Are retrieval and generator versions tracked independently
- Are evaluation metrics aligned with business KPIs
- Is index freshness monitored
RAG is not a binary capability. It is an iterative system.
When designed thoughtfully, it improves factual grounding and auditability. When treated casually, it introduces hidden complexity.
The engineering discipline applied around retrieval often determines whether RAG becomes a strategic asset or a fragile layer in the stack.