Multimodal Safety Is Harder Than Text Safety
A model that only reads text lives in a relatively predictable world. The moment we allow it to see images or listen to audio, that world becomes far less controlled.
In many enterprise discussions recently, the assumption has been that multimodal capability is simply an incremental feature upgrade. Add vision. Add audio. Expand use cases.
What I am observing instead is a structural shift in the safety surface area.
Text alignment was complex. Multimodal alignment is qualitatively harder.
Let me unpack why.
Why Text Only Alignment Felt Manageable
Text models operate within a constrained input space. Tokens are sequential. Prompt injection is visible. Moderation pipelines are comparatively straightforward.
In a text only pipeline, the safety flow moves from user input through a text moderation classifier, the LLM, and output moderation.
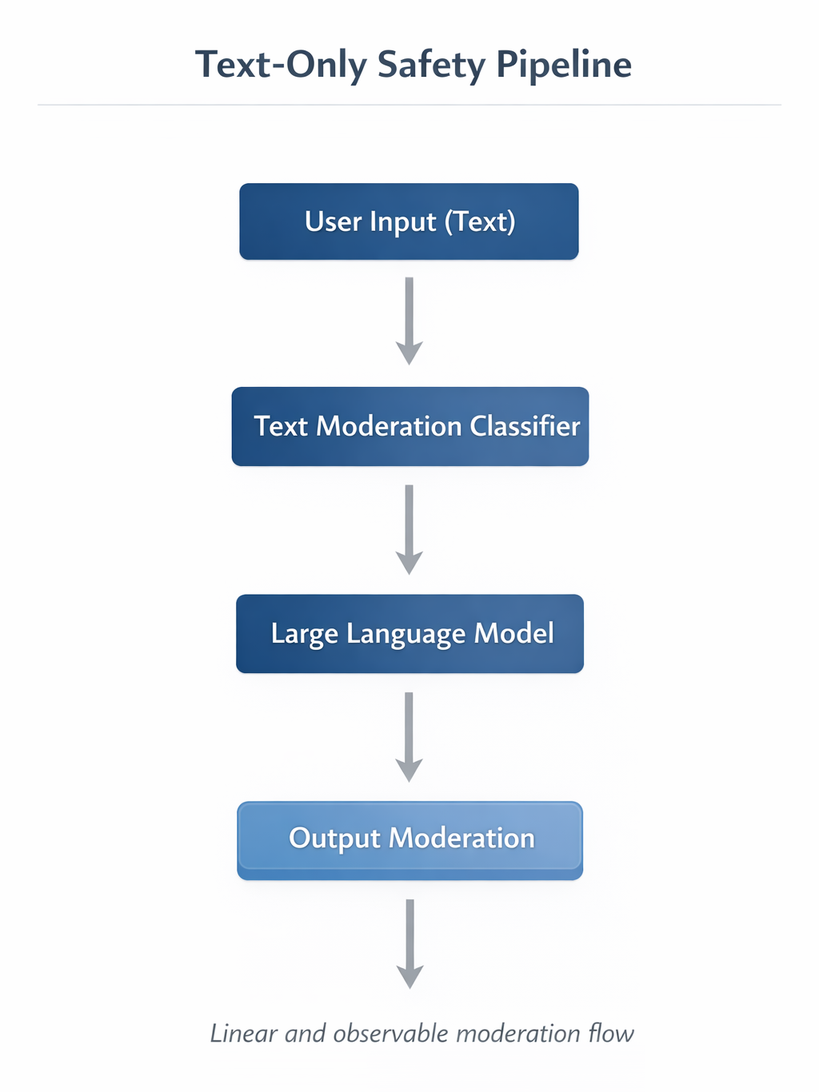
The threat model is mostly semantic. We are concerned with:
- Harmful instructions
- Policy violations
- Sensitive content leakage
- Jailbreak attempts
While difficult, the attack vectors are observable. A red team can review prompts and outputs. Logging is deterministic. Tokenization is consistent.
Even adversarial prompting still remains within the same symbolic channel.
With multimodal systems, that containment disappears.
New Multimodal Attack Surfaces
1. Vision Based Prompt Injection
When a model accepts images, the prompt no longer lives only in text.
An attacker can embed instructions inside an image. These can be:
- Text hidden in background pixels
- Subtle overlays in a screenshot
- Printed instructions within a photographed document
A human might not interpret these as commands. A vision language model might.
For example, consider systems built on models such as OpenAI multimodal GPT variants or Google Gemini family models. These models are trained to extract textual and contextual meaning from images. That capability becomes a vulnerability when instructions are embedded visually.
Unlike text prompt injection, this is harder to audit. The injected instruction is inside pixel space, not visible in raw input logs unless the image itself is stored and analyzed.
The moderation pipeline must now reason about what the model might infer, not just what the user typed.
2. Audio Spoofing and Real Time Manipulation
Audio introduces another dimension.
Voice input systems, especially those using speech to text front ends, can be attacked through:
- Synthetic voice cloning
- Real time adversarial noise
- Hidden commands embedded at frequencies difficult for humans to perceive
A system built on speech recognition pipelines and models such as Whisper can be highly robust in clean conditions. But real time environments introduce unpredictable distortions.
Consider an enterprise voice assistant for internal operations. If an attacker can spoof executive voice authorization, the risk is not theoretical.
In addition, streaming audio systems complicate moderation. You do not receive the full input at once. You receive partial tokens in real time. Safety decisions must operate under incomplete context.
Text moderation assumed discrete inputs. Audio forces probabilistic gating.
3. Safety Classifier Drift
Multimodal systems often use separate classifiers:
- Vision moderation models
- Audio toxicity detection
- Text harm classifiers
Each classifier is trained independently. Over time, they drift.
For instance:
- The vision classifier may block graphic imagery but allow symbolic hate gestures
- The text classifier may detect explicit slurs but miss coded language
- The audio classifier may struggle with accents or noisy environments
Alignment consistency across modalities becomes fragile.
Drift across classifiers can create inconsistent user experiences. Worse, attackers can probe for modality specific weaknesses.
This is not just a model problem. It is a systems integration problem.
Moderation Pipeline Redesign
Multimodal systems require a redesigned pipeline.
Instead of linear filtering, we now need layered, cross modal reasoning:
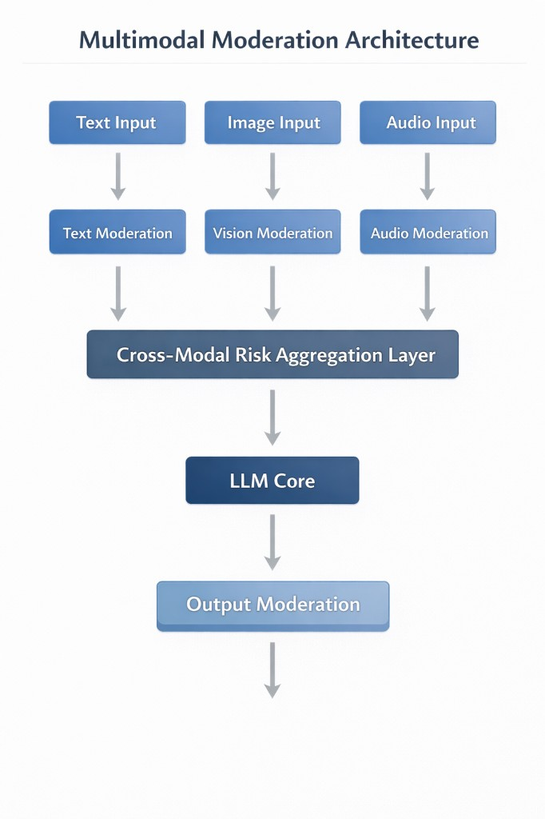
The aggregation layer becomes critical. If an image appears benign but text extracted from it contains policy violations, who decides?
If audio transcription is uncertain, should the system block or request confirmation?
Enterprises need:
- Unified policy definitions across modalities
- Risk scoring frameworks, not binary allow or block
- Replayable logging of raw multimodal inputs
- Forensic pipelines for incident review
Without this redesign, safety gaps will emerge silently.
Red Teaming Multimodal Systems
Traditional red teaming focused on prompt engineering tricks.
Multimodal red teaming must expand into:
- Adversarial image perturbations
- Hidden visual instructions
- Voice cloning simulations
- Cross modality conflict testing
Testing must include combined scenarios.
For example: an image containing a subtle instruction, plus a user text asking the model to summarize the image, plus an internal policy boundary. These compound interactions are where failures often surface.
Red teaming needs interdisciplinary skills now. Computer vision expertise. Signal processing knowledge. Human factors awareness.
Enterprise Mitigation Controls
From an architectural perspective, I see several mitigation controls becoming standard:
- Image Sanitization Layers: Strip embedded metadata. Detect suspicious overlays. Normalize resolution.
- Audio Authentication Controls: Voice fingerprint validation for high risk commands. Challenge response patterns.
- Contextual Confidence Thresholds: If cross modal signals conflict, reduce autonomy and require human review.
- Separate Safety Budgets: Do not assume a text aligned model is automatically multimodal safe.
- Versioned Safety Models: Treat moderation models as production services with monitoring, rollback, and drift detection.
The governance function must expand accordingly.
Governance Updates Needed Now
Multimodal systems require updates across policy and compliance layers:
- Data retention rules for images and audio
- Consent requirements for voice processing
- Incident classification frameworks specific to multimodal misuse
- Board level visibility into multimodal risk exposure
Risk registers must explicitly include:
- Vision prompt injection
- Audio spoofing
- Cross modality inconsistency
This is not fear driven thinking. It is architectural realism.
A Forward Looking Architectural Lens
If text safety taught us how to moderate language, multimodal safety is teaching us how to moderate perception.
Enterprises that treat vision and audio as simple extensions of text pipelines may discover blind spots too late.
My working lens is this:
- Every new modality increases capability
- Every new modality multiplies the attack surface
- Safety must be multimodal by design, not retrofitted
The models are improving quickly. That is exciting.
But safety architecture must evolve just as quickly, or faster.
That is the real design challenge ahead.