Model Evaluation is the Missing Layer in GenAI Systems
Generative AI systems have seen rapid adoption across enterprises. Teams are building chat assistants, copilots, document summarizers, search interfaces, and workflow automations at unprecedented speed.
Yet, in many architectures I review, one layer is consistently underdeveloped:
Model evaluation.
We have prompts.
We have vector databases.
We have orchestration layers.
We have CI/CD pipelines.
But we do not yet have evaluation systems that match the complexity and risk of these deployments.
I increasingly believe that evaluation is the missing operational layer in GenAI systems.
1. The Real Problem: We Are Deploying Behavior
Traditional software validation looks like this:
Input → Function → Deterministic Output → Assert EqualityGenerative systems look like this:
Input → Context → Prompt → LLM → Probabilistic Output
There is no single "correct" answer.
There is only quality, relevance, safety, and alignment.
That changes everything.
Without structured evaluation:
- Hallucinations go unnoticed
- Prompt regressions slip into production
- Retrieval pipelines degrade silently
- Safety boundaries erode
And teams only discover issues when users complain.
2. Where Evaluation Should Sit in the Architecture
Most GenAI stacks today follow a RAG-style pattern:
User → Retriever → Context → Prompt Template → LLM → ResponseWe often optimize:
- Embedding quality
- Chunking strategy
- Prompt engineering
- Caching
- Latency
But evaluation is frequently manual and ad hoc.
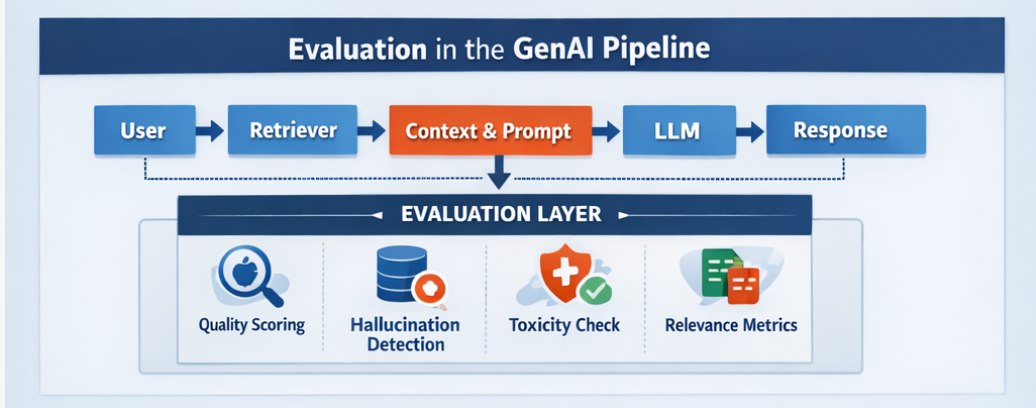
The evaluation layer must not be optional.
It must be continuous.
3. Types of Evaluation We Actually Need
1. Prompt Regression Testing
Every prompt change can shift behavior significantly.
You need:
- Fixed test datasets
- Representative user queries
- Edge cases
- Adversarial inputs
And you must compare:
- Response relevance
- Tone consistency
- Format compliance
Prompt versioning without regression evaluation is dangerous.
2. Retrieval Quality Evaluation (For RAG Systems)
In retrieval-augmented generation systems, many hallucinations are retrieval failures.
Evaluate:
- Top-k relevance
- Context precision
- Context recall
- Over-chunking vs under-chunking
If your retriever fails, your LLM compensates.
That compensation often looks like hallucination.
3. LLM Output Quality Scoring
Common approaches include:
- Human evaluation (gold standard, expensive)
- LLM-as-a-judge scoring
- Rule-based validators
- Structured output validation
None are perfect.
All are necessary.
The key is triangulation.
4. Safety and Policy Evaluation
Generative systems must be tested for:
- Toxicity
- Prompt injection
- Jailbreak attempts
- Data leakage
- Sensitive information exposure
Evaluation is not only about quality.
It is about risk containment.
4. Offline vs Online Evaluation
We must separate:
Offline Evaluation
- Pre-deployment testing
- Controlled benchmark datasets
- Structured scoring
Online Evaluation
- A/B testing prompts
- Real user feedback signals
- Drift detection
- Failure clustering
Both are essential.
Offline evaluation prevents obvious regressions.
Online evaluation reveals real-world complexity.
5. Metrics Are Not Enough
Traditional ML had clear metrics:
- Accuracy
- Precision
- Recall
- F1
- ROC-AUC
GenAI requires multi-dimensional metrics:
- Helpfulness
- Faithfulness
- Relevance
- Coherence
- Safety
- Format compliance
Some of these are subjective.
That is uncomfortable for engineers.
But avoiding subjectivity does not remove it.
It only hides it.
6. Why Teams Skip Evaluation
Teams skip formal evaluation because:
- It slows perceived velocity
- It is harder to automate
- There is no single "correct" metric
- Tooling is still maturing
However, the cost of skipping evaluation appears later:
- Brand damage
- User trust erosion
- Escalating support tickets
- Regulatory scrutiny
Evaluation is not overhead.
It is infrastructure.
7. A Practical Minimal Evaluation Stack
If I were starting today, I would implement:
- Curated evaluation dataset (50–500 real queries)
- Prompt versioning with explicit change logs
- Automated batch testing before deployment
- LLM-based grading for relevance and faithfulness
- Manual spot audits weekly
- Production logging with structured failure tags
This does not require perfection.
It requires discipline.
8. Connecting Evaluation to Responsible AI
Evaluation is not separate from responsibility.
It directly supports:
- Fairness tracking
- Transparency through documented behavior
- Ongoing accountability
Strong evaluation practices are a concrete operationalization of responsible AI principles.
9. The Emerging Pattern
We are moving through three stages:
- Experimentation
- Deployment
- Operationalization
Evaluation is the bridge between deployment and operationalization.
Without it, GenAI systems remain demos.
With it, they become infrastructure.
Closing Thoughts
Generative AI systems are not traditional software.
They are behavioral systems operating under uncertainty.
That means:
- We cannot rely on static unit tests.
- We cannot rely on intuition.
- We cannot rely on best-case demos.
We must build evaluation as a first-class architectural component.
If you are deploying GenAI without systematic evaluation,
you are deploying blind.
And in production systems,
blind deployment is not a strategy.