Model Audit Trails and Observability
During the past year, we have collectively moved from asking "Can this model work?" to asking something far more important:
"Can we trust it in production?"
As AI systems move deeper into customer workflows, internal automation, analytics, and decision support, one thing has become clear to me:
Building the model is only the beginning. Operating it responsibly is the real challenge.
Two concepts are emerging as foundational to mature AI systems:
- Model audit trails
- Observability
They are related, but not the same. And together, they form the backbone of production grade AI governance.
Let us unpack what that means.
1. From Logging to Accountability
Traditional application logging captures:
- Requests
- Errors
- Latency
- System metrics
But LLM powered systems introduce a different kind of operational surface:
- Prompts
- Context injection
- Retrieved documents
- Model parameters
- Generated outputs
- Confidence signals
- Human overrides
We are no longer just logging system behavior. We are logging decision behavior.
That is where audit trails become critical.
2. What Is a Model Audit Trail?
A model audit trail is a structured, queryable history of every inference event, including:
- User input
- System prompt
- Retrieved context
- Model version
- Temperature and decoding parameters
- Output
- Post processing steps
- Human feedback
- Timestamp and user identity where appropriate
In simple terms:
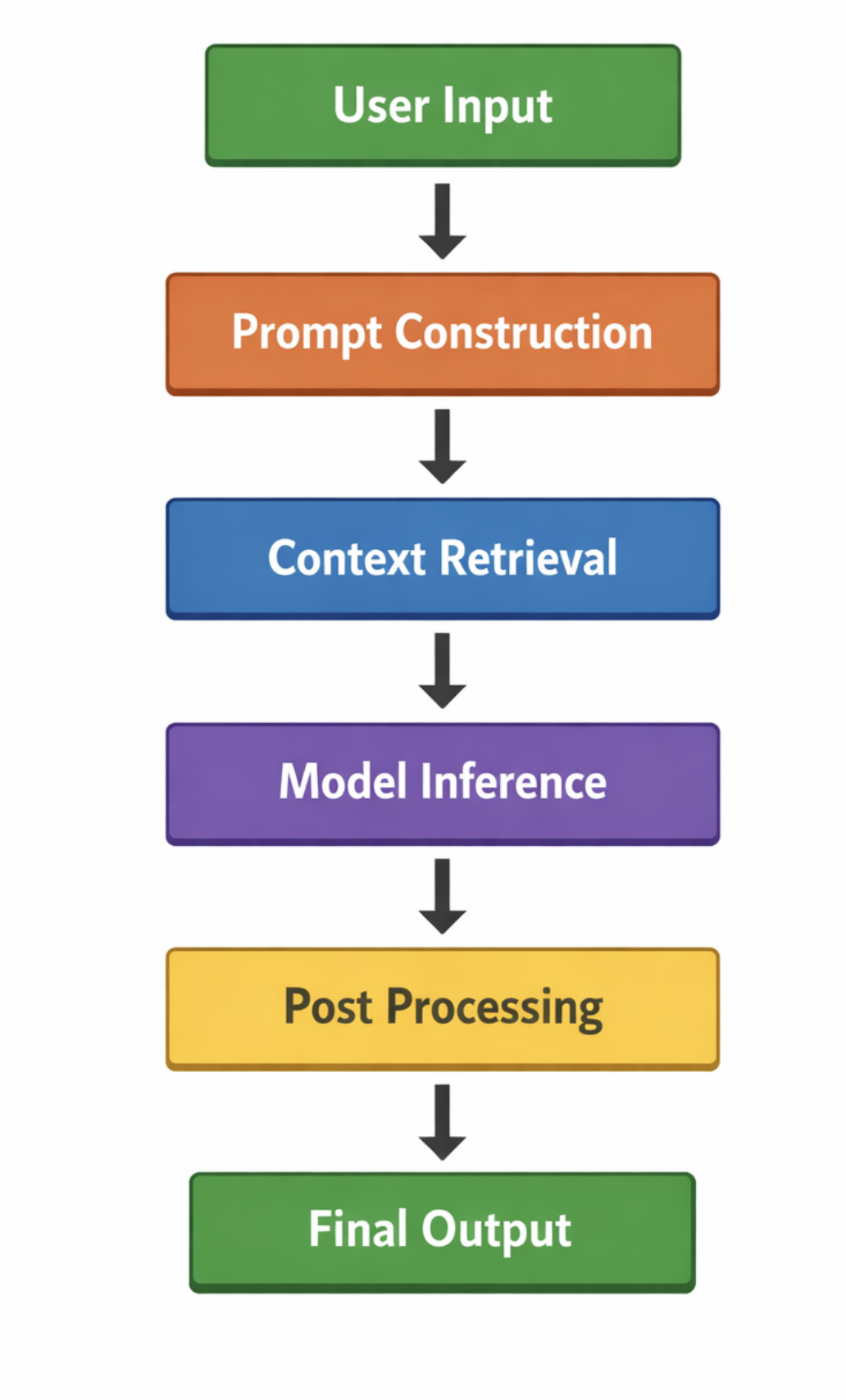
Every step above should be reconstructible after the fact.
If a customer disputes a response, or compliance raises a concern, or a regulator asks for explanation, the system must be able to answer:
- What data influenced this output?
- Which model produced it?
- Under what configuration?
- Was there a human override?
Without this, governance becomes guesswork.
3. Observability Is Broader Than Audit
If audit trails are about traceability, observability is about system health and behavior trends.
In traditional distributed systems, observability covers:
- Metrics
- Logs
- Traces
For AI systems, it expands to include:
- Output quality drift
- Hallucination frequency
- Latency distribution by prompt type
- Token consumption trends
- Cost per request
- Retrieval accuracy
- Confidence routing distribution
We are not just monitoring uptime. We are monitoring behavioral stability.
4. The AI Observability Stack
In production AI systems, I increasingly see an architectural pattern like this:
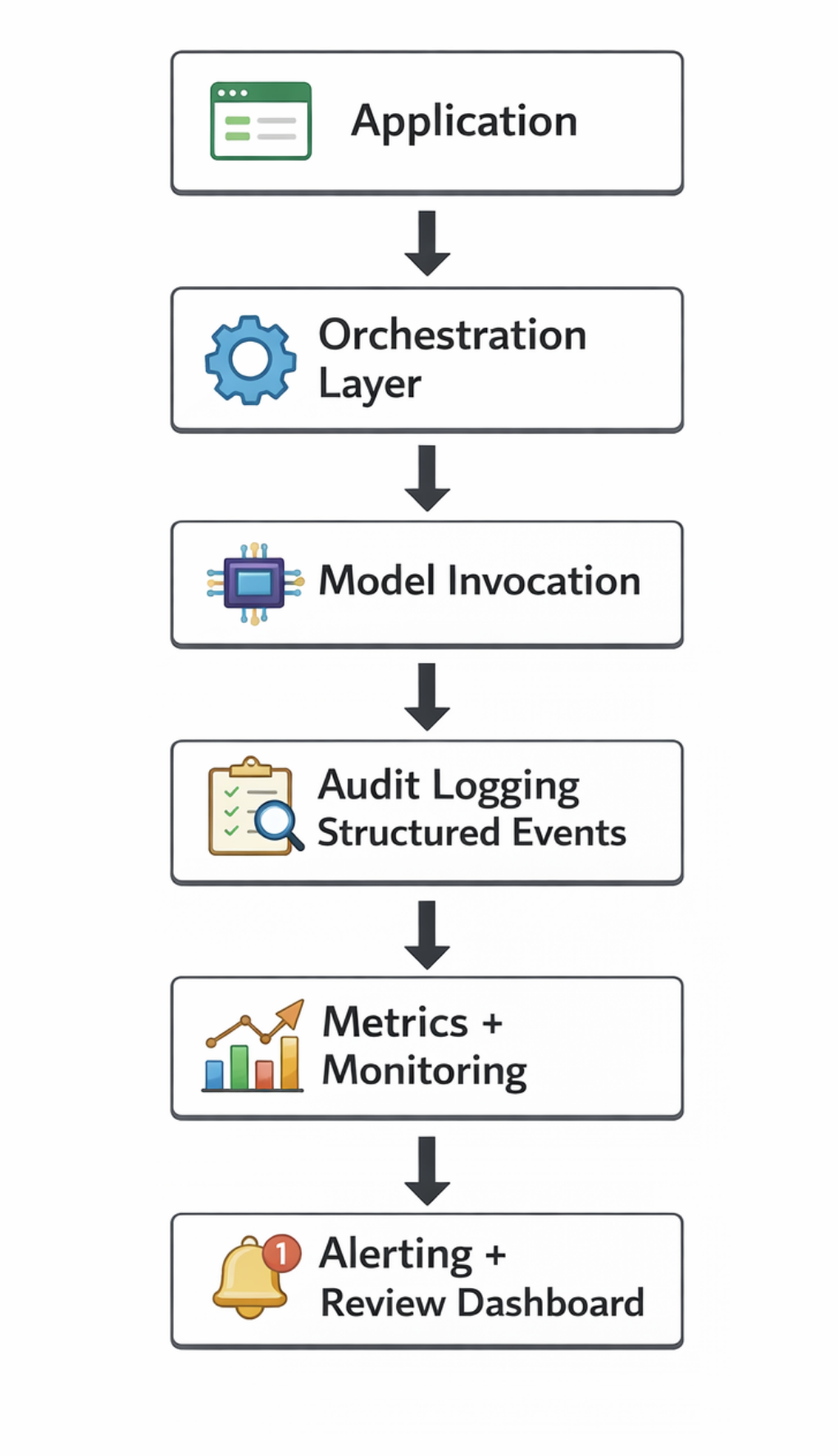
The critical insight is this:
Audit logging should not be an afterthought bolted on later. It should be embedded at the orchestration layer.
That is where prompts are assembled, retrieval occurs, and routing decisions are made.
5. Why This Matters Now
There are several forces converging:
1. Enterprise Risk Committees
Leadership teams are increasingly asking for documentation around AI decisions.
2. Customer Transparency
Customers want to know how their data is used.
3. Model Iteration Velocity
Models are evolving quickly. Without traceability, regressions are invisible.
4. Cost Visibility
Token usage and large model invocations can create silent cost escalations.
Audit trails give you explainability. Observability gives you control.
Together, they give you credibility.
6. Key Design Principles
From practical implementations, a few principles stand out:
Log Structured Data, Not Just Text
Instead of storing a single blob log, capture structured fields:
- model_version
- prompt_hash
- retrieval_doc_ids
- routing_decision
- confidence_score
- user_segment
- latency_ms
- token_count
Structured logs allow aggregation and analysis.
Version Everything That Influences Behavior
Not just model version.
Also version:
- Prompt templates
- Retrieval index
- Reranking logic
- Guardrails
- Post processors
If it changes output behavior, it must be versioned.
Separate Sensitive and Non Sensitive Logs
AI audit trails often include user inputs. That introduces privacy risk.
Design systems so that:
- Sensitive raw inputs are encrypted or redacted
- Derived metrics are stored separately
- Access controls are enforced strictly
Governance must include data minimization.
Monitor Behavioral Drift
Observability should include:
- Output length distribution changes
- Sentiment shifts
- Confidence score trends
- Escalation frequency in routing systems
Drift is rarely obvious in single requests. It appears in aggregate patterns.
7. The Cultural Shift
One thing I have learned over the years is that tools alone do not create reliability. Culture does.
For AI systems, this means:
- Treating prompts like production code
- Running post incident reviews for bad outputs
- Maintaining dashboards that leadership can understand
- Creating ownership for model health
Observability is not just a technical layer. It is an operational discipline.
8. A Practical Maturity Model
Organizations typically move through stages:
Stage 1
Basic logging of inputs and outputs
Stage 2
Structured inference records with model versions
Stage 3
Cost tracking and token analytics
Stage 4
Behavioral dashboards and alerting
Stage 5
Formal audit readiness and compliance review workflows
Most teams today are somewhere between Stage 1 and Stage 2.
That is understandable. The ecosystem is still maturing. But the gap between experimentation and enterprise readiness is largely an observability gap.
Closing Thoughts
AI systems are probabilistic. That does not mean they should be opaque.
If anything, the probabilistic nature of generative systems demands stronger audit trails and deeper observability than traditional software ever required.
When something goes wrong in a deterministic system, you inspect the code path. When something goes wrong in an AI system, you must inspect:
- Data
- Prompts
- Routing
- Model configuration
- Human feedback loops
Without an audit trail, you cannot reconstruct reality. Without observability, you cannot detect degradation early.
As we continue embedding AI deeper into business critical workflows, these two layers will quietly become the difference between experimental systems and production systems that leadership truly trusts.
And in my view, trust is the real infrastructure we are building.