From Bench to Deployment: Building Robust ML Systems in 2025
A model that performs beautifully in a notebook can still fail spectacularly in production.
That gap between experimentation and deployment continues to be one of the most underestimated engineering challenges in machine learning. I have been part of multiple conversations this year where teams celebrated benchmark wins, only to discover that integration, observability, and lifecycle management became the real bottlenecks.
Building robust ML systems is no longer about model architecture alone. It is about system architecture.
Let me walk through how I am seeing mature teams approach this transition from bench to deployment.
The End to End Implementation Pattern
At a high level, robust ML systems are built around explicit lifecycle stages. The teams that move fastest are the ones who treat this as an engineering discipline, not a research experiment.
A common reference architecture looks like this:
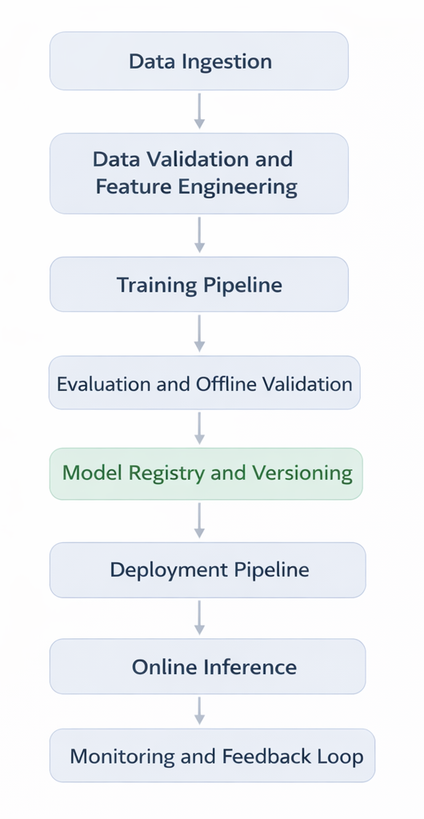
Each block is owned, observable, and version controlled.
Data Ingestion and Validation
Data pipelines are now first class citizens in ML system design. Silent schema changes are among the most common causes of production failures.
Mature implementations include:
- Schema enforcement with automated checks
- Feature distribution tracking
- Data lineage tagging
- Reproducible dataset snapshots
Feature stores have become foundational in many enterprises. They reduce training serving skew by ensuring that the same transformation logic is applied both offline and online.
Training Pipelines as Code
Notebook driven experimentation still exists, but production training pipelines are fully codified.
Key patterns include:
- Containerized training jobs
- Declarative pipeline definitions
- Reproducible environment specifications
- Automated hyperparameter sweeps
- Artifact logging
Training outputs are not just model weights. They include metadata, metrics, configuration, and dependency hashes.
This metadata becomes critical when debugging performance regressions months later.
Model Registry as the System of Record
The model registry has evolved into the control plane for ML systems.
It typically stores:
- Model artifacts
- Training configuration
- Evaluation metrics
- Approval status
- Deployment history
This enables traceability. When a model underperforms in production, teams can quickly correlate version, dataset, and training run.
Observability: Treat Models Like Production Services
One of the biggest mindset shifts I have observed is this, models are now treated as services with SLOs.
We monitor more than accuracy.
Key Production Metrics
- Latency percentiles
- Throughput
- Error rates
- Resource utilization
- Feature distribution drift
- Prediction distribution drift
Drift detection deserves special attention.
Data Drift vs Concept Drift
- Data drift refers to changes in input feature distributions
- Concept drift refers to changes in the relationship between inputs and outputs
Data drift is easier to detect using statistical tests such as KL divergence or population stability index. Concept drift often requires labeled feedback or proxy metrics.
A simplified monitoring loop looks like this:
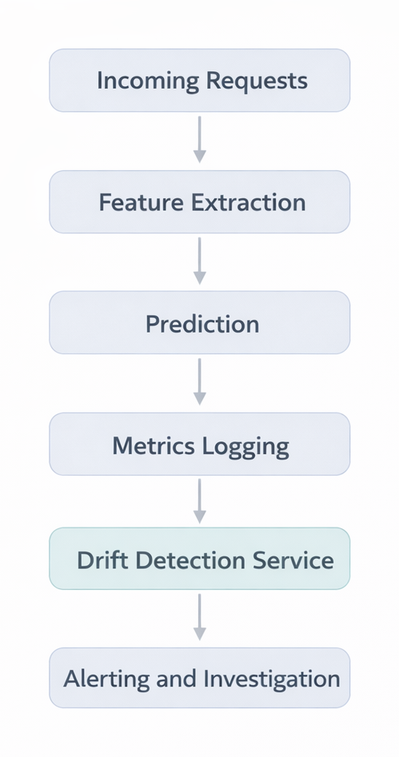
In robust systems, drift alerts are tied to automated workflows, not manual dashboards alone.
A B Testing and Controlled Rollouts
Deploying a new model version is not a binary switch anymore.
Progressive delivery patterns are becoming standard.
Common Rollout Strategies
- Shadow deployment
- Canary release
- Percentage based traffic splitting
- Segment specific routing
A simplified traffic split looks like this:
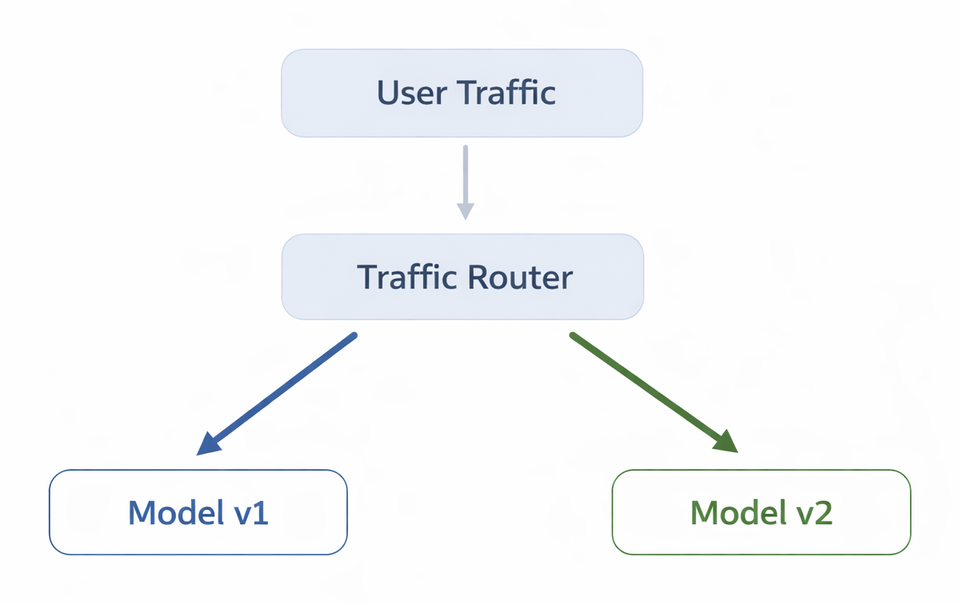
A B testing for models focuses on:
- Business metrics
- Fairness metrics
- Latency impact
- User behavior shifts
It is important to define success criteria before rollout. Without predefined evaluation metrics, experiments become anecdotal.
Rollback Mechanisms and Safety Nets
One of the most important operational lessons is this, every deployment must be reversible.
Rollback mechanisms typically include:
- Instant traffic reversion
- Version pinning
- Immutable model artifacts
- Configuration rollback
Infrastructure as code principles now extend to model serving stacks. Blue green deployments are common, where two environments run in parallel and traffic shifts only after validation.
The worst position to be in is discovering a degraded model with no clean way to revert.
Drift Detection and Continuous Learning Loops
Robust ML systems are not static.
Drift detection triggers one of three actions:
- Alert only
- Trigger retraining pipeline
- Automatic rollback
The retraining loop typically follows:
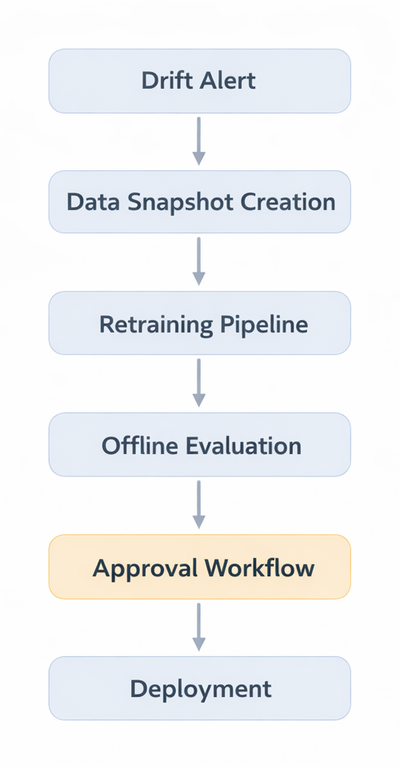
Human oversight remains essential, especially in regulated environments. Fully autonomous retraining is rare outside low risk domains.
MLOps Tooling Maturity in 2025
Tooling maturity has improved significantly, but fragmentation still exists.
What Has Stabilized
- Experiment tracking systems are standardized in most enterprises
- Model registries are integrated with CI CD pipelines
- Infrastructure automation is expected
- Feature stores are widely adopted
Where Complexity Remains
- Cross team governance
- Multi cloud deployments
- Cost monitoring for large models
- Unified observability across batch and real time systems
Teams are increasingly creating internal ML platforms rather than stitching tools ad hoc.
These internal platforms provide:
- Standardized pipeline templates
- Centralized registry
- Integrated monitoring
- Automated compliance checks
- Cost dashboards
The result is reduced cognitive load for application teams.
Organizational Implications
Technical maturity alone is not enough.
The teams that succeed in deployment share certain characteristics:
- Clear ownership boundaries
- Defined model approval workflows
- Shared metrics between data science and platform teams
- Incident response playbooks for model degradation
ML engineering has become a hybrid discipline combining software engineering, data engineering, and statistical thinking.
Bench performance is necessary, but operational resilience determines impact.
A Practical Deployment Checklist
When evaluating whether a model is truly ready for production, I use a simple checklist:
- Is the training dataset versioned and reproducible?
- Are offline metrics aligned with business KPIs?
- Is there a clear rollback strategy?
- Are drift thresholds defined?
- Are latency SLOs measured under peak load?
- Is monitoring automated and alert driven?
- Is the model registered with complete metadata?
If any of these answers are unclear, the system is not ready.
Moving from bench to deployment is not a linear upgrade. It is a shift in discipline.
In 2025, robust ML systems are defined less by their parameter count and more by their operational rigor. The real differentiator is not how fast we can train a model, but how confidently we can run it in the wild.
That is where engineering depth truly shows.