Engineering Reasoning Models: Production Challenges in Debugging & Evaluating Chains of Thought
We are at a point where models can narrate their thinking beautifully, yet still fail on a carefully constructed logic task. That paradox is forcing many of us to rethink what we mean by reasoning in production systems.
In multiple architecture reviews and deployment discussions, one theme keeps emerging. Improving reasoning quality is not just about better prompts or larger models. It demands new evaluation strategies, new debugging workflows, and tighter CI discipline.
Let us go deeper into what reasoning models actually are, how they differ from vanilla LLMs, and why productionizing them introduces a new class of engineering challenges.
What Makes a Reasoning Model Different?
A vanilla large language model optimizes for next token prediction conditioned on context. It is extraordinarily good at pattern continuation. It may appear to reason, but internally it is performing probabilistic sequence modeling.
A reasoning oriented model changes the inference pattern.
Instead of:
Prompt → Model → AnswerWe now have:
Prompt → Intermediate reasoning steps → Final answerThis intermediate phase may be:
- Explicit chain of thought text
- Hidden internal reasoning tokens
- Structured intermediate state representations
- Multi step tool invocation
The key distinction is not just output verbosity. It is structural. The model is encouraged or trained to decompose a task into smaller logical units before producing a conclusion.
This decomposition creates benefits:
- Improved performance on arithmetic and symbolic tasks
- Better constraint tracking
- More stable multi step reasoning
But it also introduces cost:
- Higher latency
- Larger token consumption
- More complex failure modes
- Increased observability requirements
Once reasoning becomes multi step, debugging becomes multi dimensional.
Failure Modes Unique to Chains of Thought
In production, I have seen reasoning systems fail in ways that look convincing at first glance.
Common patterns include:
- Constraint Dropout: A condition is correctly extracted early but silently ignored in later steps.
- Arithmetic Drift: Intermediate calculations accumulate small errors that propagate to the final result.
- Logical Shortcutting: The model jumps to a plausible answer without fully executing all steps.
- Overconfident Summarization: The reasoning trace contains uncertainty, yet the final answer is phrased as definitive.
The difficult part is this: the reasoning trace often appears coherent. That coherence can mask subtle logical inconsistencies.
Unlike single shot generation errors, reasoning failures require step level inspection.
Why Single Shot Metrics Are Not Enough
Traditional evaluation pipelines rely on metrics such as exact match accuracy or final answer correctness.
For reasoning models, this is incomplete.
If we only measure the final answer, we miss:
- Whether constraints were extracted correctly
- Whether intermediate steps were logically valid
- Whether the model's reasoning was stable across paraphrases
A more robust evaluation approach includes:
1. Structured Step Evaluation
Force structured output:
{
"parsed_constraints": [...],
"intermediate_steps": [...],
"final_answer": ...
}Each component can be validated independently.
For example:
- Constraint validation via rule checking
- Arithmetic verification via deterministic computation
- Logical consistency scoring
This converts reasoning from opaque text into testable components.
2. Adversarial Logic Sets
Reasoning models often perform well on familiar benchmark distributions. They become fragile when confronted with compositional edge cases.
Adversarial sets should include:
- Variable renaming
- Reordered constraints
- Distractor statements
- Nested conditional logic
- Counterfactual scenarios
The goal is not to trick the model. The goal is to stress test logical consistency under structural perturbation.
If performance collapses under mild rephrasing, the reasoning is brittle.
3. Multi Pass Consistency Checks
One practical method is to run the same reasoning problem multiple times with slight input perturbations and measure answer variance.
High variance indicates unstable reasoning.
For mission critical systems, this variance signal can trigger fallback mechanisms.
CI/CD for Reasoning Systems
Reasoning models require a more software like engineering discipline.
Treat reasoning tasks as logic functions, not creative generation.
1. Unit Tests for Logic
Maintain a reasoning regression suite:
- Arithmetic problems
- Constraint satisfaction tasks
- Domain specific reasoning workflows
- Edge case scenarios
Example test structure for arithmetic:
def test_reasoning_arithmetic(model):
prompt = "If X is 4 more than Y and Y is 6, what is X?"
result = model(prompt)
assert extract_final_answer(result) == 10For structured reasoning:
def test_constraint_extraction(model):
result = model(structured_prompt)
assert validate_constraints(result["parsed_constraints"])This ensures logical regressions are caught before deployment.
2. Checkpoint Comparisons
When upgrading models:
- Compare final accuracy
- Compare intermediate reasoning length
- Compare constraint retention rate
- Track failure category shifts
A new model may improve accuracy but degrade stability under perturbation. Without structured regression suites, this goes unnoticed.
3. Logical Drift Monitoring in Production
In live systems, monitor:
- Sudden spikes in reasoning token length
- Increased arithmetic error frequency
- Distribution changes in failure categories
- Increased variance across repeated queries
Reasoning degradation is rarely binary. It often appears as drift.
Monitoring these signals allows early intervention.
Hybrid Architectures for Deterministic Tasks
One architectural pattern that repeatedly proves useful is hybrid reasoning.
User Query
↓
LLM extracts structured variables
↓
External deterministic module validates or computes
↓
LLM produces final explanation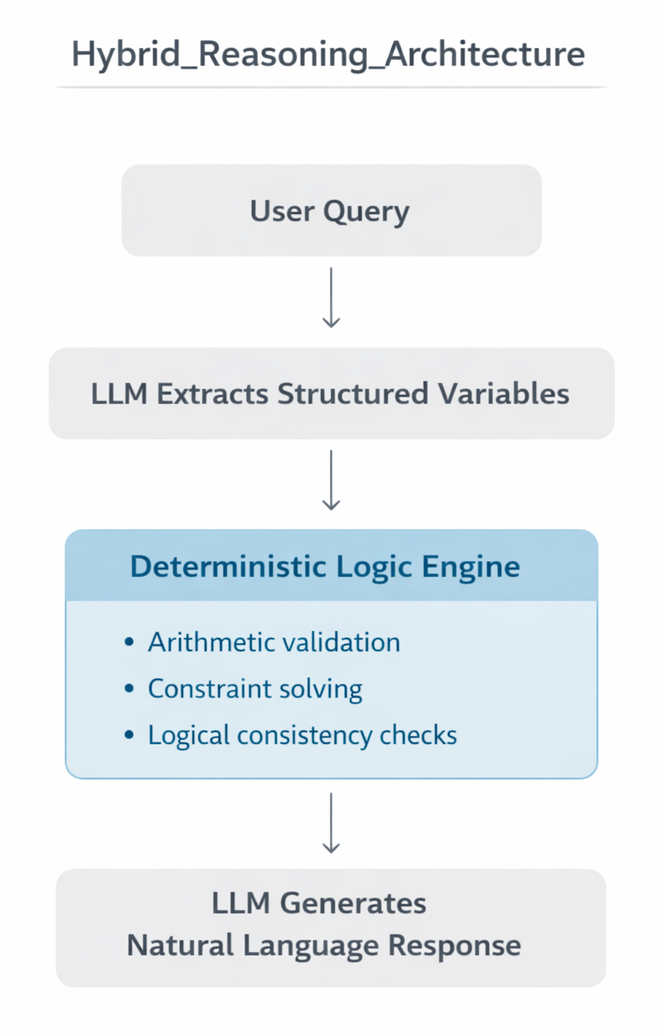
The LLM handles language understanding and explanation. The deterministic module handles strict logic.
This separation improves:
- Debuggability
- Deterministic correctness
- Auditability
- Compliance readiness
It also aligns with a pragmatic reality. Neural reasoning is powerful but probabilistic. Deterministic engines remain superior for strict symbolic validation.
Practical Checklist Before Production Rollout
Before deploying a reasoning model, ask:
- Do we validate intermediate reasoning steps?
- Do we maintain a structured regression suite for logic tasks?
- Have we tested under paraphrasing and adversarial perturbations?
- Do we monitor reasoning drift in production?
- Do we have deterministic fallbacks for critical logic paths?
If the answer to most of these is no, the system is relying on optimistic assumptions.
Reasoning models are impressive. They extend what language models can do. But production engineering demands discipline beyond impressive demos.
The real shift is not from prompts to reasoning. It is from generation systems to cognitive pipelines that must be versioned, tested, monitored, and governed like any other mission critical subsystem.