CI/CD for LLM Systems: What Changes?
Teams have moved rapidly from experimenting with Large Language Models to embedding them in production systems. Traditional CI/CD thinking is not enough for LLM-powered applications.
We are no longer deploying only code.
We are deploying behavior.
That single shift changes how we version, test, deploy, monitor, and roll back systems. Let's break down what actually changes when we introduce LLMs into a production pipeline.
1. The Core Shift: Deterministic Code → Probabilistic Behavior
Traditional software pipelines assume:
- Deterministic outputs
- Stable logic paths
- Clear pass/fail test outcomes
LLM systems introduce:
- Probabilistic outputs
- Behavior shaped by prompts and context
- Non-binary quality signals
Your CI/CD pipeline must expand from code validation to behavior validation.
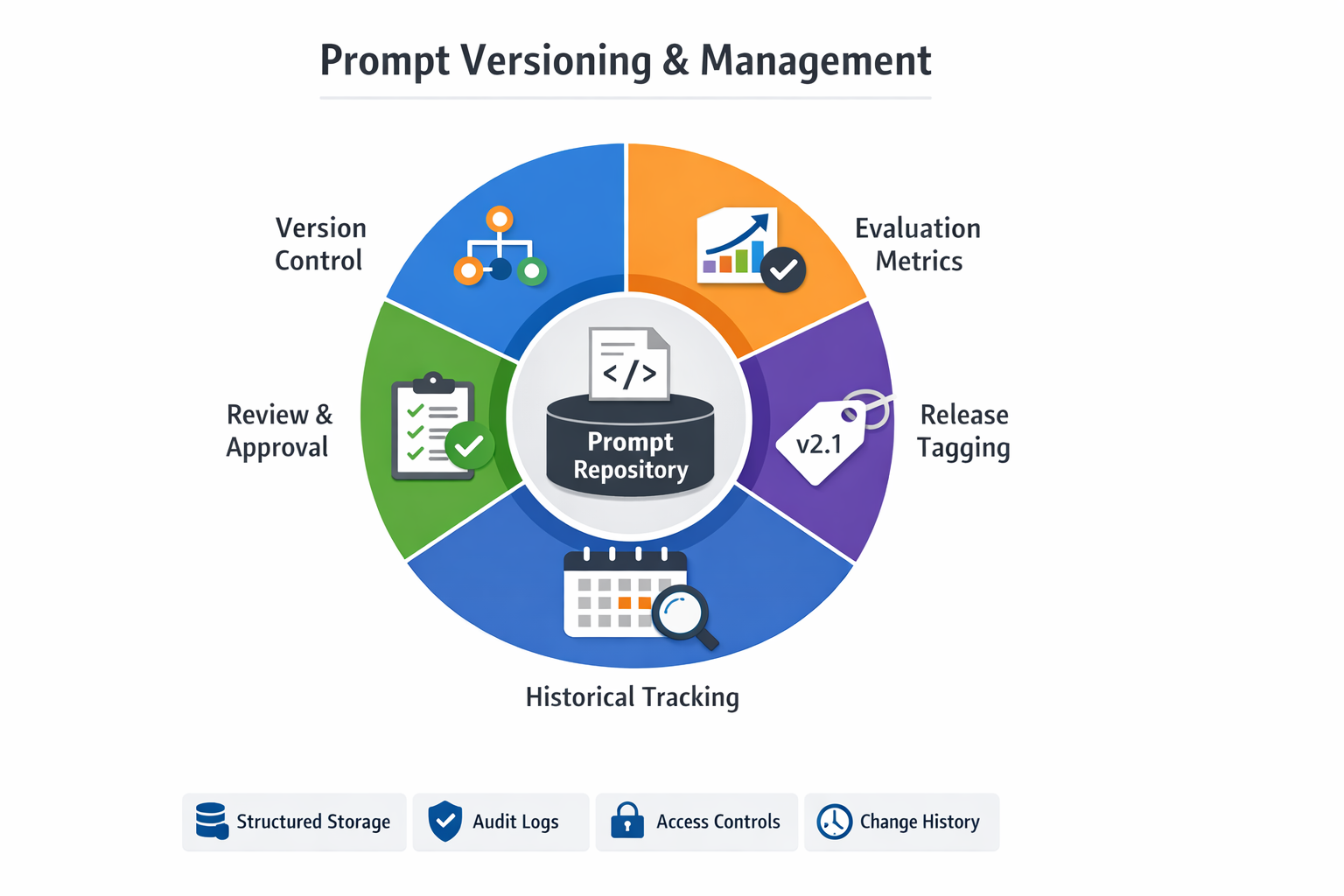
2. Prompt Versioning Becomes First-Class
In classical systems, we version source code. In LLM systems, prompts are just as critical as application logic.
A small wording change can:
- Increase hallucination
- Shift tone
- Change factual grounding
- Alter reasoning depth
- Impact cost per request
Yet many teams still treat prompts as inline strings inside code.
That is a mistake.
What Should Change
Prompts should be:
- Stored as structured artifacts
- Version controlled
- Tagged with releases
- Associated with evaluation metrics
- Reviewed before promotion
A production-ready setup should allow you to answer:
- Which prompt version was active on July 20?
- What metrics did Prompt v3.2 achieve?
- When did hallucination rate increase?
If you cannot answer those questions quickly, your system is not operationally mature.
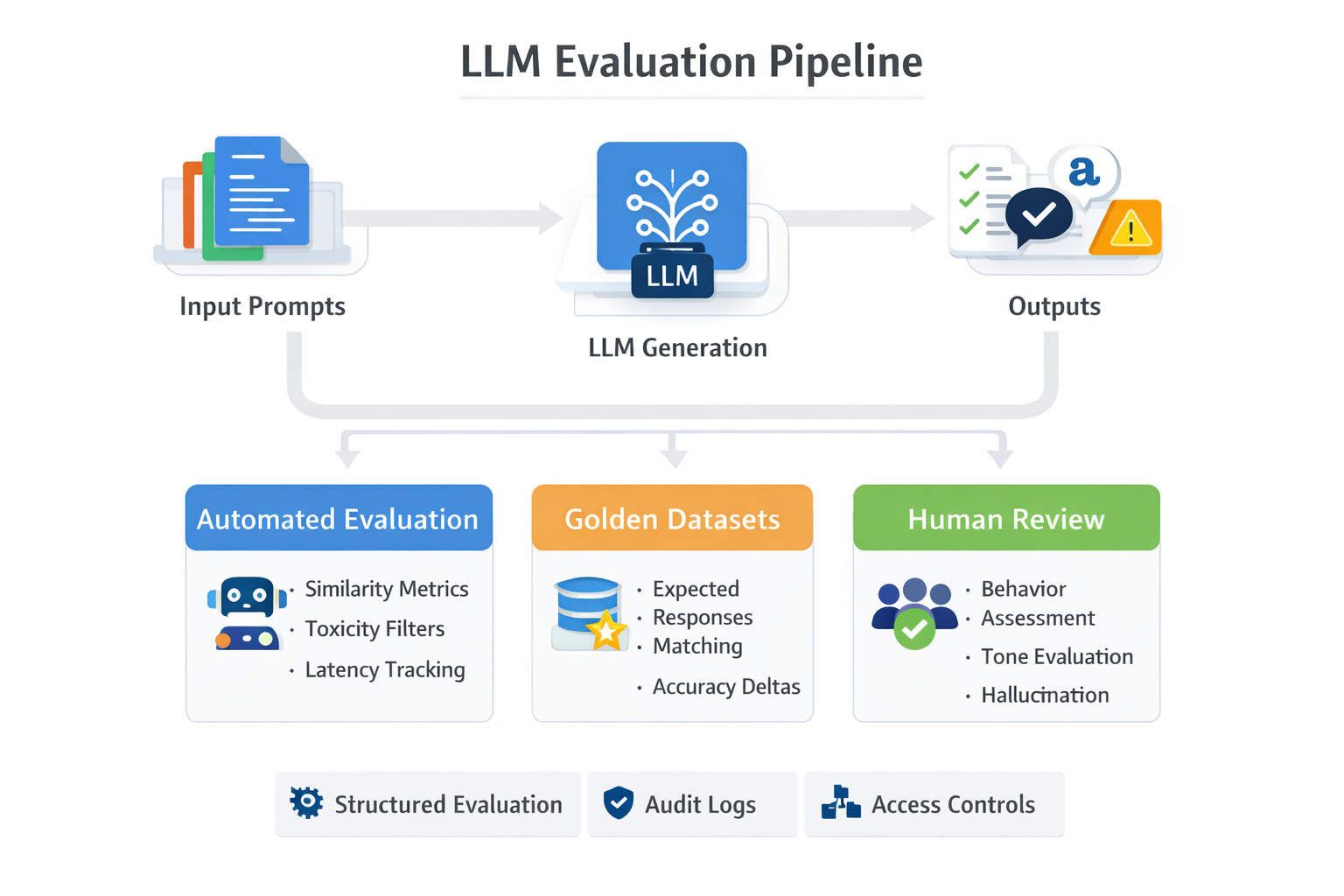
3. Evaluation Pipelines Replace Simple Unit Tests
Traditional CI runs unit tests. LLM CI must run evaluation suites.
Because outputs are open-ended, evaluation becomes layered:
Automated Evaluation
- Similarity metrics (embedding similarity)
- Structured output validation
- Toxicity checks
- Safety filters
- Latency measurements
- Cost tracking
Golden Datasets
Curated input-output pairs representing expected behavior.
Every CI run should compare:
- New prompt/model vs previous version
- Accuracy deltas
- Safety shifts
- Performance regressions
Human-in-the-Loop Sampling
Automated scoring is not enough.
Periodic sampled human review catches:
- Subtle reasoning degradation
- Tone drift
- Overconfidence
- Hallucination patterns
In LLM systems, deployment should be gated by behavior thresholds, not just test pass/fail.
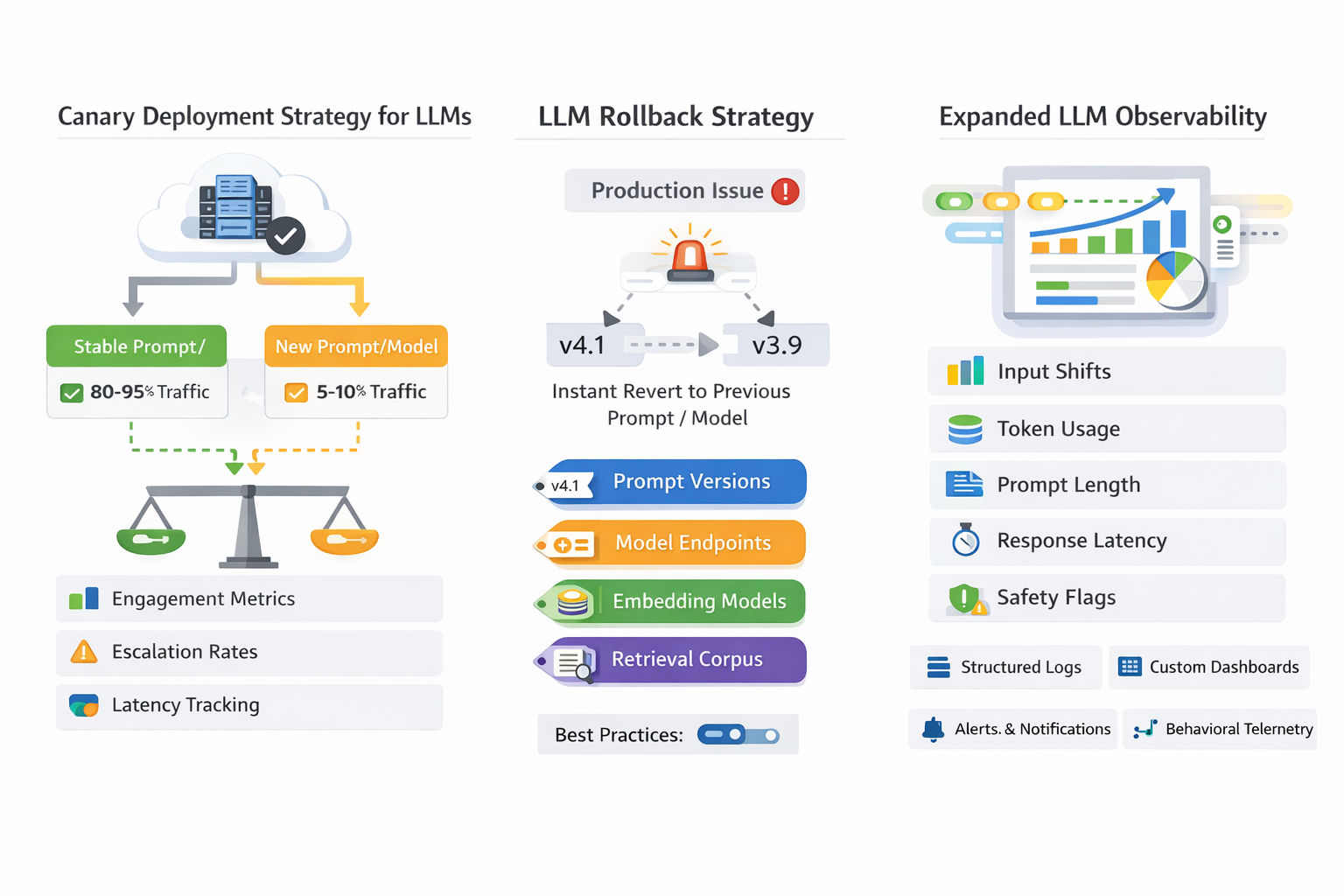
4. Canary Deployments Become Essential
With deterministic systems, we worry about crashes.
With LLM systems, we worry about quality drift.
A prompt tweak that looks fine offline can behave differently at scale.
Canary Deployment Strategy for LLMs
- Route 5–10% of traffic to the new prompt/model
- Keep majority traffic on stable version
- Compare:
- Engagement metrics
- Escalation rates
- User feedback
- Cost per request
- Latency
- Safety flags
Unlike traditional services, LLM canaries should also include qualitative sampling.
Metrics may not tell you the full story; especially for reasoning systems.
5. Rollback Strategies Must Be Instant and Multi-Dimensional
Rollback in classical systems means reverting code.
Rollback in LLM systems may require reverting:
- Prompt versions
- Model endpoints
- Embedding models
- Retrieval corpus snapshots
- Evaluation configuration
Best Practices
- Immutable artifacts
- Version-tagged prompt bundles
- Environment-specific configuration isolation
- Feature flags controlling prompt activation
If hallucination spikes in production, recovery must take minutes, not hours.
Operationally, this means:
- You should be able to flip traffic back to the previous prompt without redeploying the entire service.
- Model selection should be configurable, not hard-coded.
6. Observability Expands
LLM observability requires tracking:
- Input distribution shifts
- Token usage
- Prompt length changes
- Response latency
- Safety filter triggers
- Cost anomalies
Logs are no longer just request/response pairs.
They are behavioral telemetry.
Without structured observability, debugging becomes guesswork.
7. What Does Not Change
Despite the differences, core engineering discipline still applies:
- Automate everything repeatable
- Keep deployments small
- Promote across environments progressively
- Monitor continuously
- Design for safe failure
CI/CD is still about reducing risk.
The difference is the surface area of risk has expanded.
8. The New Mental Model
In traditional systems:
Code → Build → Test → Deploy
In LLM systems:
Prompt + Model + Retrieval + Config → Evaluate → Compare → Canary → Monitor → Deploy
We are no longer shipping binaries.
We are shipping evolving probabilistic systems.
Treat prompts, evaluations, and behavior metrics as first-class deployment artifacts, or accept operational chaos.
Teams that operationalize this will move faster with less risk.
And in production AI systems, discipline is the real competitive advantage.