Batching, Quantization, and Distillation Strategies
How do we make AI systems efficient enough to operate at scale?
Capability without efficiency does not survive contact with real infrastructure constraints. Latency targets, cloud bills, concurrency spikes, and reliability requirements quickly force architectural discipline.
Three techniques consistently emerge in serious deployments:
- Batching
- Quantization
- Distillation
Let me share how I think about these strategies when designing production grade AI systems.
1. Batching, Improving Throughput Without Changing the Model
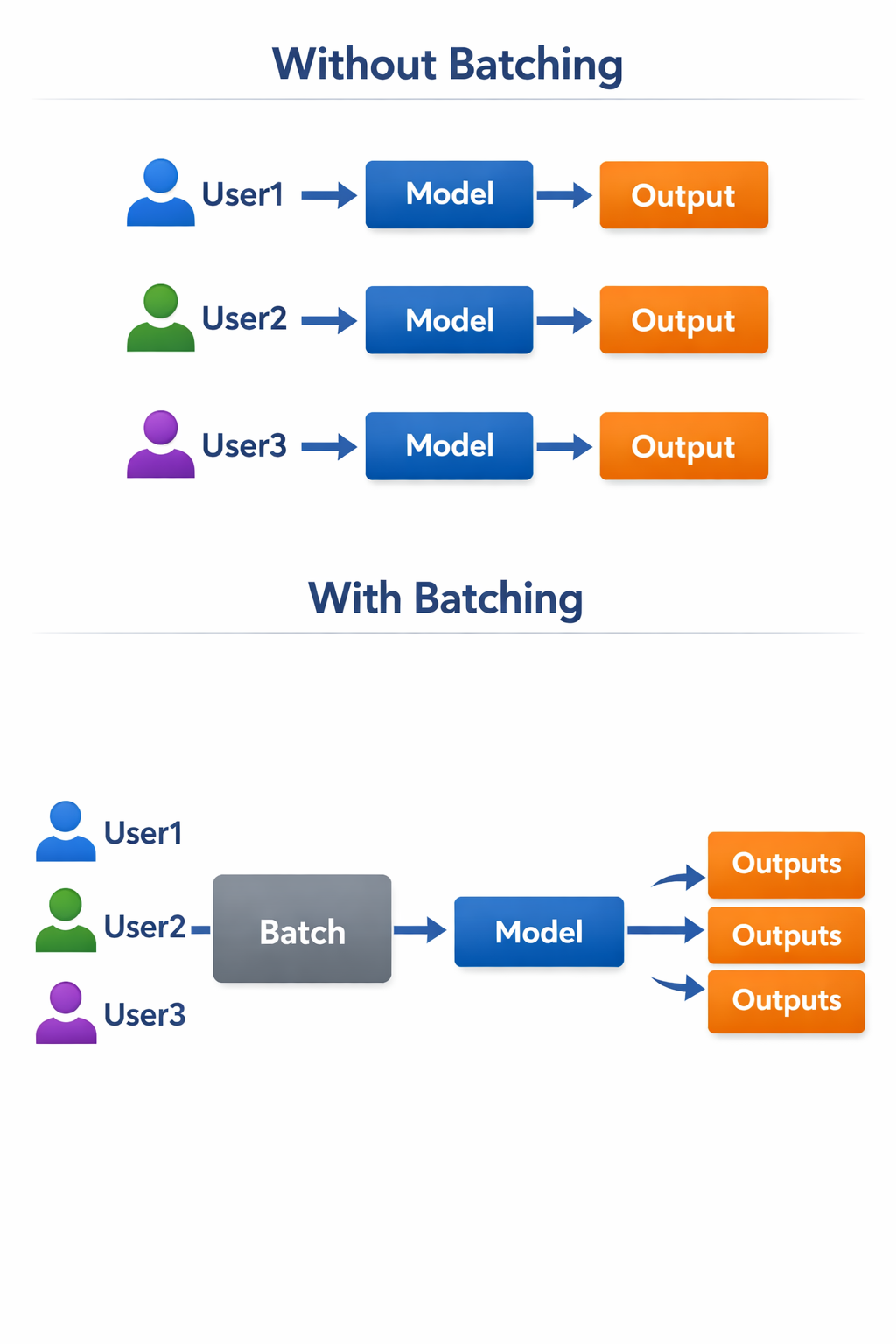
Batching is conceptually simple. Instead of sending one request at a time to a model, we group multiple requests and process them together.
This is especially powerful for GPU based inference, where parallelism is abundant but underutilized with single request workloads.
Why Batching Matters
Modern accelerators are optimized for matrix operations. If you send one small inference request, much of the GPU remains idle. When you send a batch, you increase hardware utilization and reduce cost per inference.
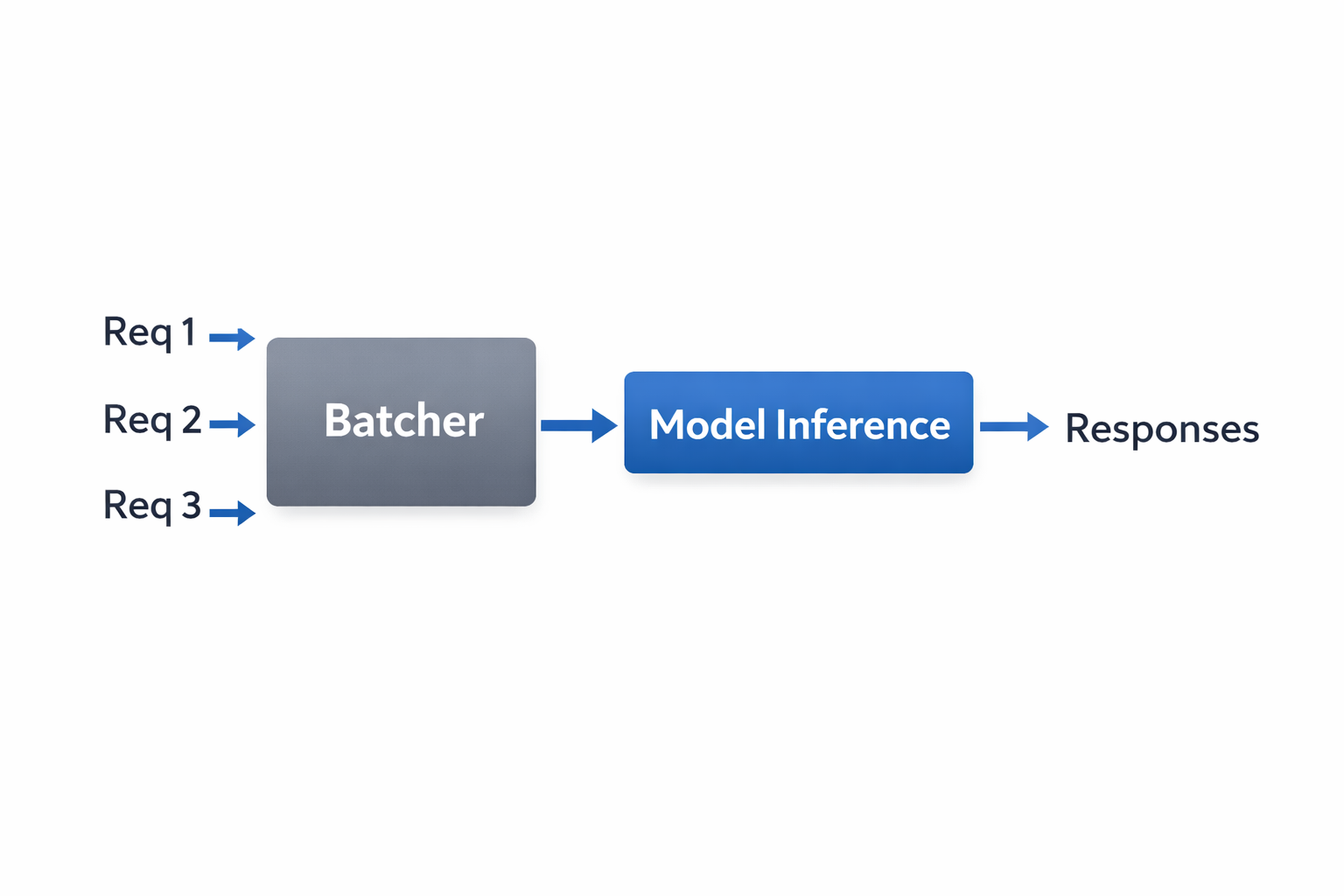
Here is a simplified flow:
Architectural View
Trade-offs
Batching increases throughput but can increase latency if not tuned carefully. In interactive systems such as chat interfaces, you often use dynamic batching with micro delays measured in milliseconds to balance user experience and cost efficiency.
In background jobs such as document processing, larger batch sizes are acceptable.
Batching does not change model quality. It changes cost structure.
2. Quantization, Reducing Precision to Reduce Cost
Quantization reduces the numerical precision of model weights and sometimes activations. Instead of 32 bit floating point numbers, we use 16 bit, 8 bit, or even lower precision representations.
Why This Works
Neural networks are often robust to small numerical noise. That tolerance allows us to reduce memory footprint and improve inference speed without significant degradation in output quality.
Impact Areas
- Lower GPU memory consumption
- Faster inference
- Ability to run larger models on smaller hardware
- Lower infrastructure cost
Conceptual Representation
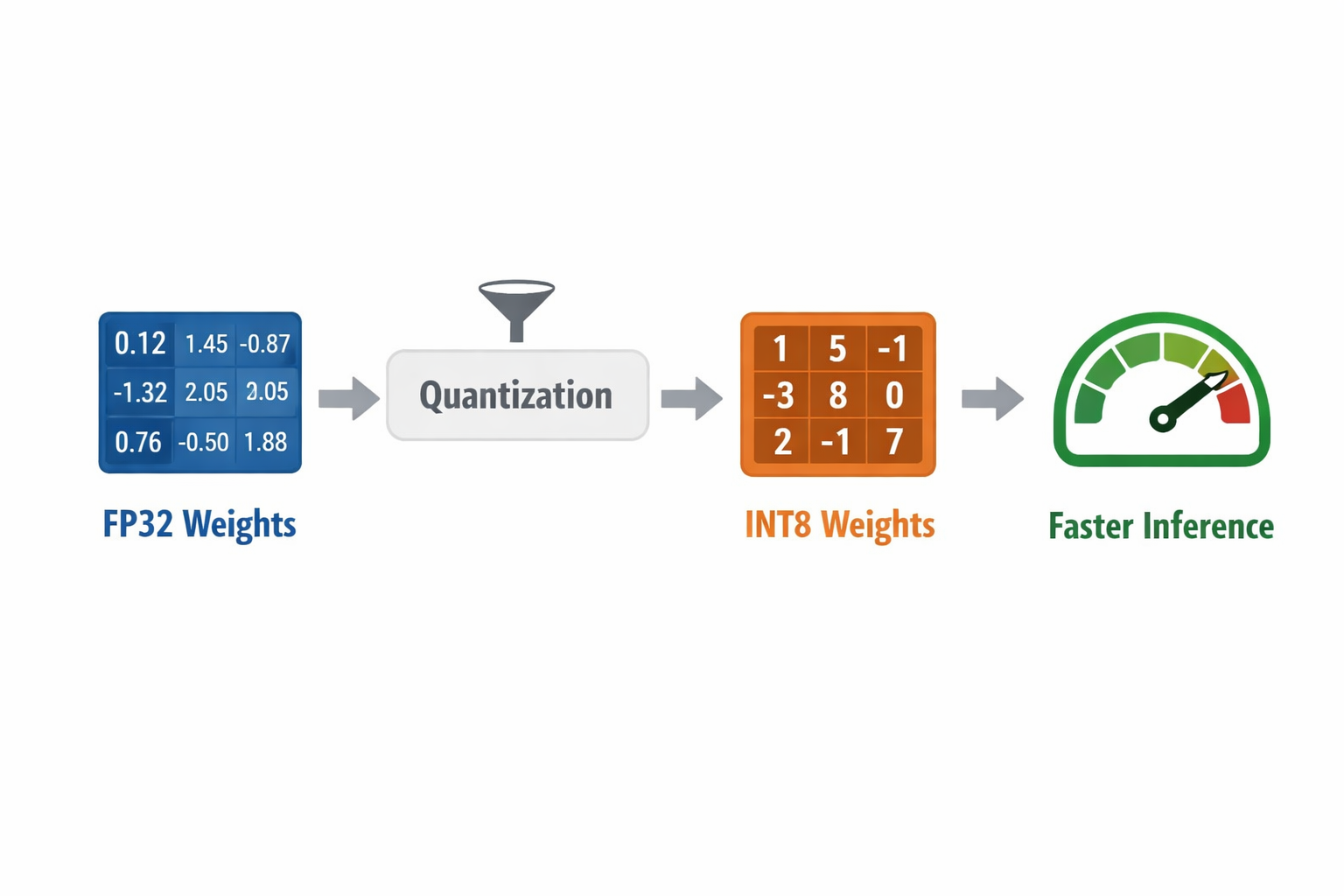
Where It Fits
Quantization is particularly valuable when deploying models at the edge, on CPU based infrastructure, or when running high concurrency APIs where memory pressure becomes a bottleneck.
The key is disciplined evaluation. Not all tasks tolerate aggressive quantization equally. Safety critical workflows require careful benchmarking before precision reduction.
3. Distillation, Transferring Knowledge to Smaller Models
Distillation is one of my favorite strategies because it balances capability with efficiency in a more structural way.
Instead of simply compressing weights, we train a smaller student model to imitate a larger teacher model.
High-Level Flow
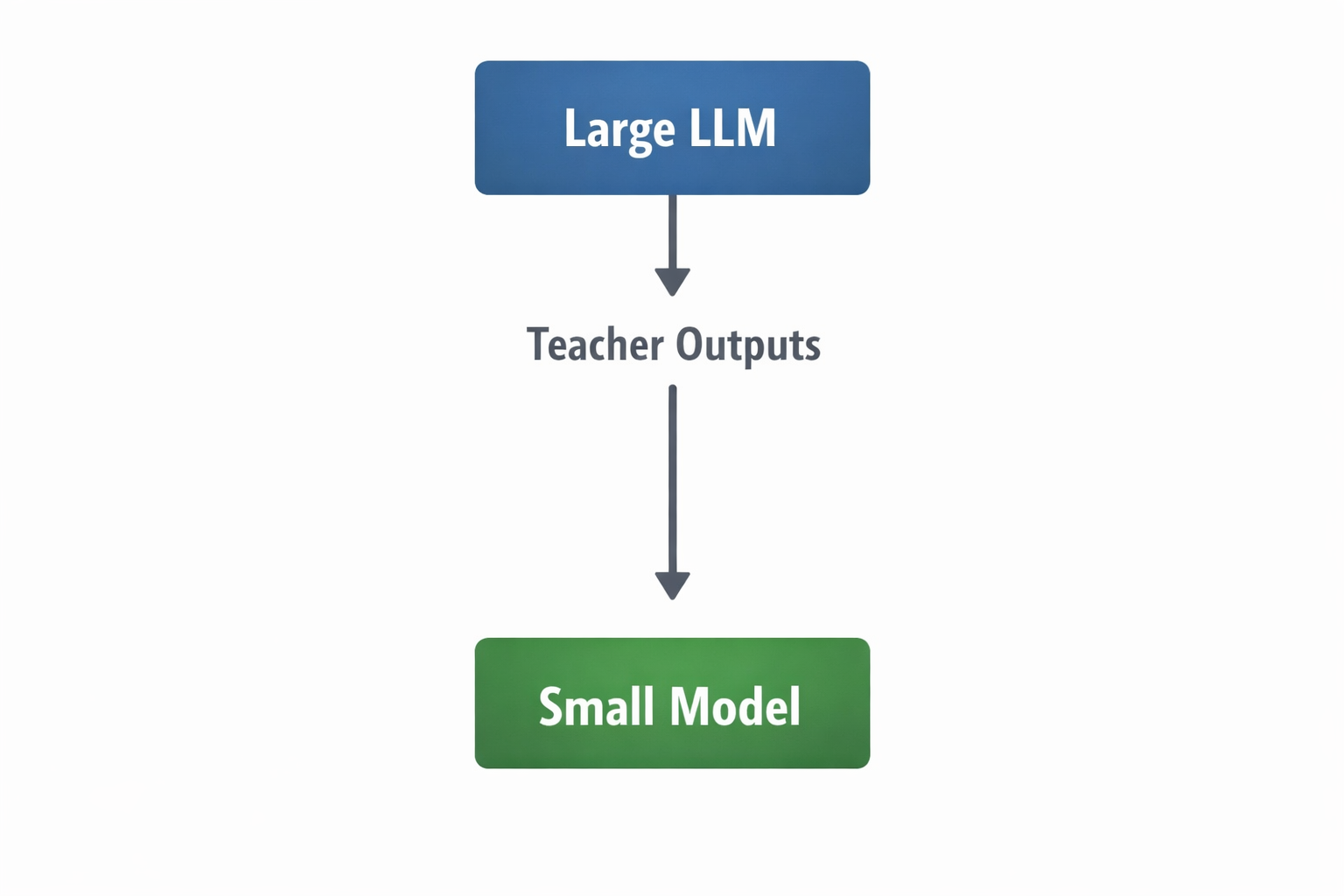
The large model generates outputs, explanations, or soft probabilities. The smaller model learns from this richer signal rather than only ground truth labels.
Why Distillation Is Powerful
- Lower inference cost
- Lower latency
- Reduced infrastructure footprint
- More predictable performance under load
Distillation is particularly useful when your production workload is narrow. For example, if your system performs structured extraction, classification, or domain specific reasoning, a distilled model can outperform a general purpose model on that specific task at a fraction of the cost.
4. Combining All Three in Production
In practice, these strategies are not isolated. Mature AI systems often combine them.
Example architecture:
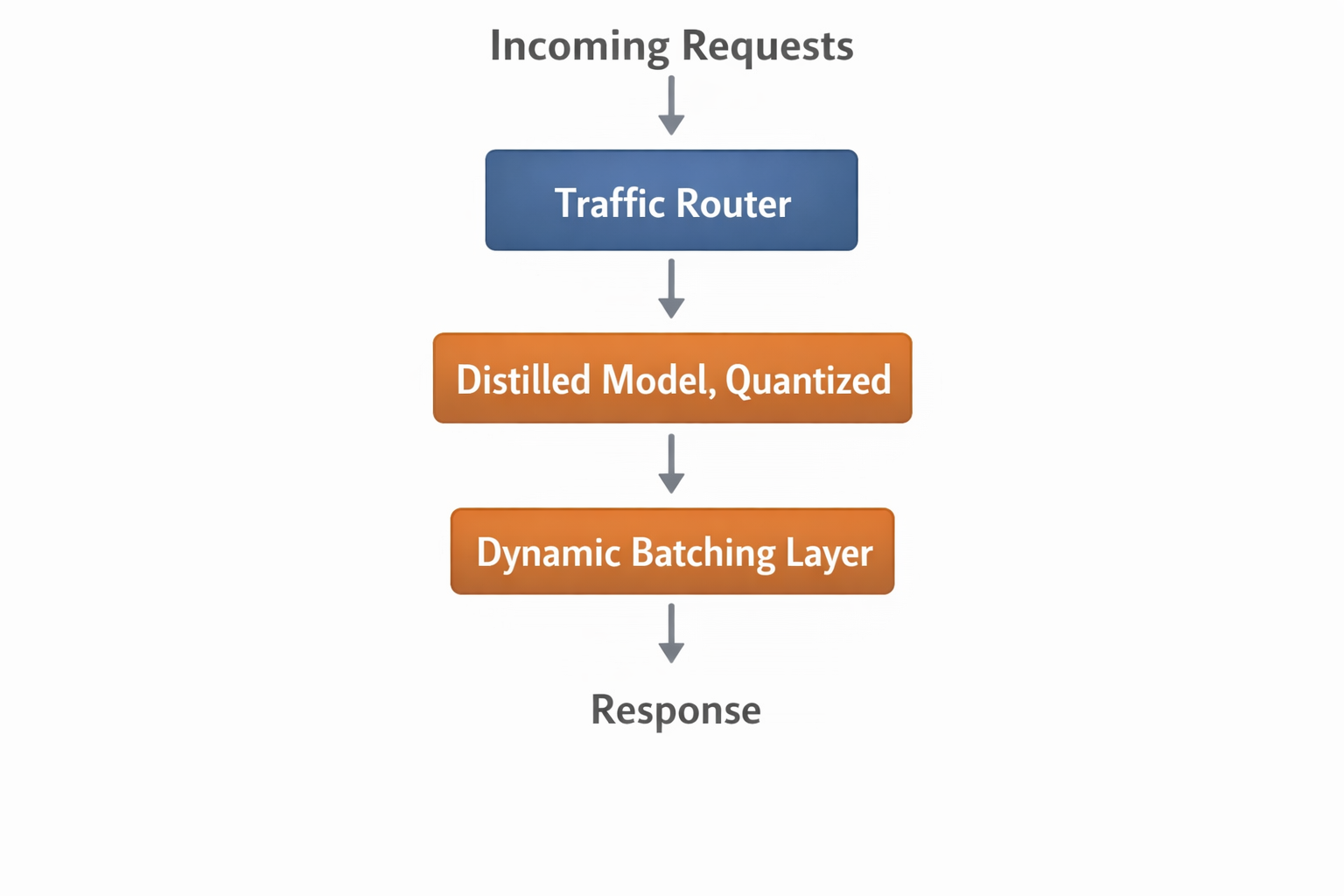
And for complex tasks:
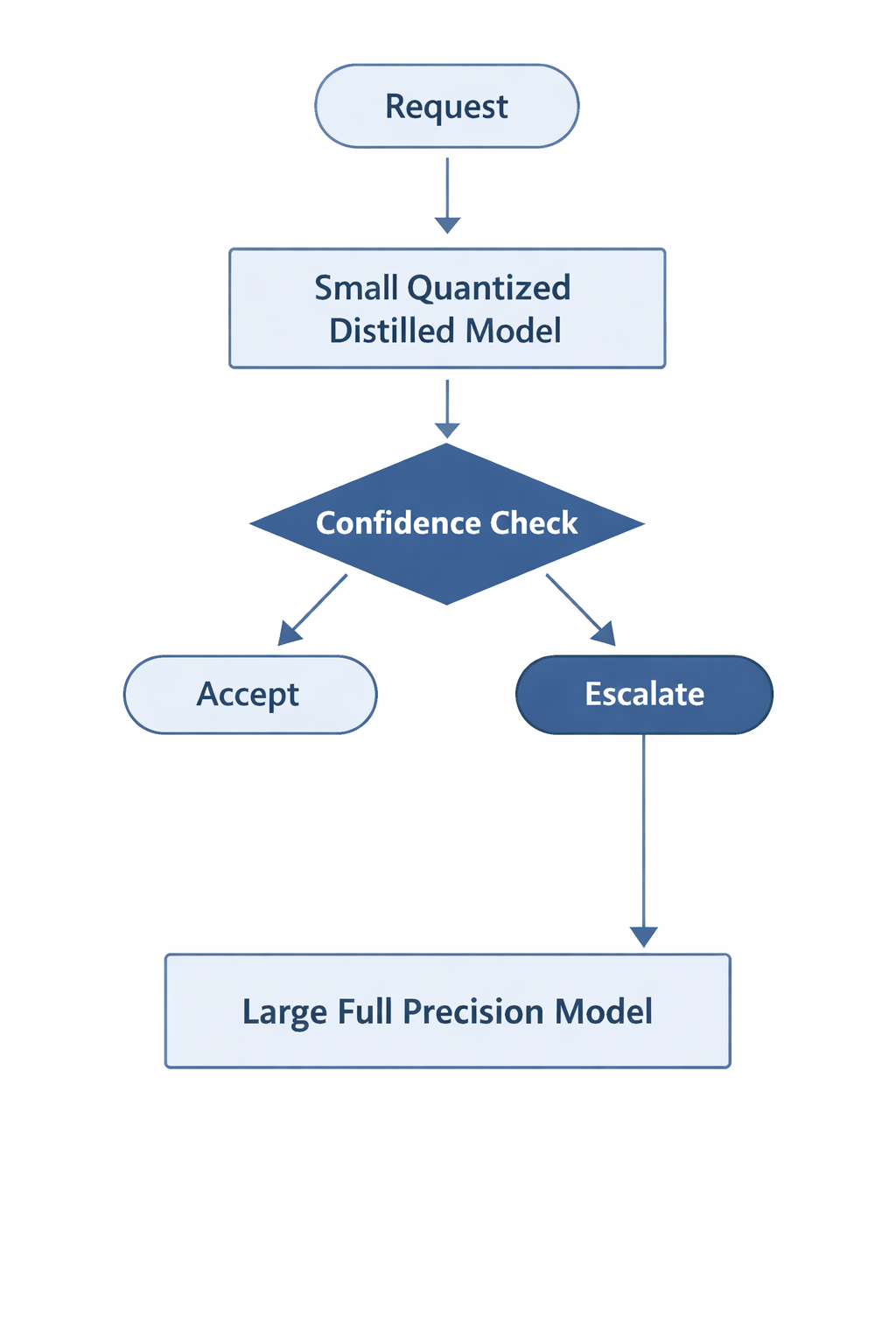
This layered approach ensures:
- High volume traffic is handled cheaply
- Edge cases are escalated
- Hardware utilization is optimized
- Quality is preserved where it matters
5. Cloud Infrastructure Perspective
When operating in cloud environments, these techniques directly affect:
- Cost per token
- GPU instance selection
- Autoscaling behavior
- Memory allocation efficiency
- Capacity planning
Batching improves GPU utilization. Quantization reduces instance size requirements. Distillation reduces dependency on expensive large models for routine tasks.
Together, they transform the economic profile of AI systems.
The shift I am observing in mature teams is subtle but important. They stop asking:
"Which model is best?"
And start asking:
"What is the cheapest architecture that meets our quality bar?"
That is the mindset required to move from experimentation to sustainable production systems.
Closing Thoughts
Efficiency is not an afterthought in AI system design. It is foundational.
Batching optimizes throughput. Quantization optimizes memory and speed. Distillation optimizes architectural strategy.
When thoughtfully combined, these techniques allow us to build AI systems that are not only powerful, but economically and operationally viable.
As we continue building increasingly capable models, I believe the real engineering challenge lies in making them practical.
And that is where thoughtful system design makes all the difference.