The Rise of RAG as the Default Architecture Pattern
A clear architectural pattern has emerged in serious AI deployments over recent years: Retrieval-Augmented Generation (RAG) has become the default design choice for production-grade AI systems.
Early experimentation leaned heavily on prompt engineering and larger models. But as systems transitioned from prototypes to enterprise platforms, one realization became unavoidable:
Large Language Models are powerful, but they are not knowledge bases.
RAG represents a disciplined architectural response to that insight.
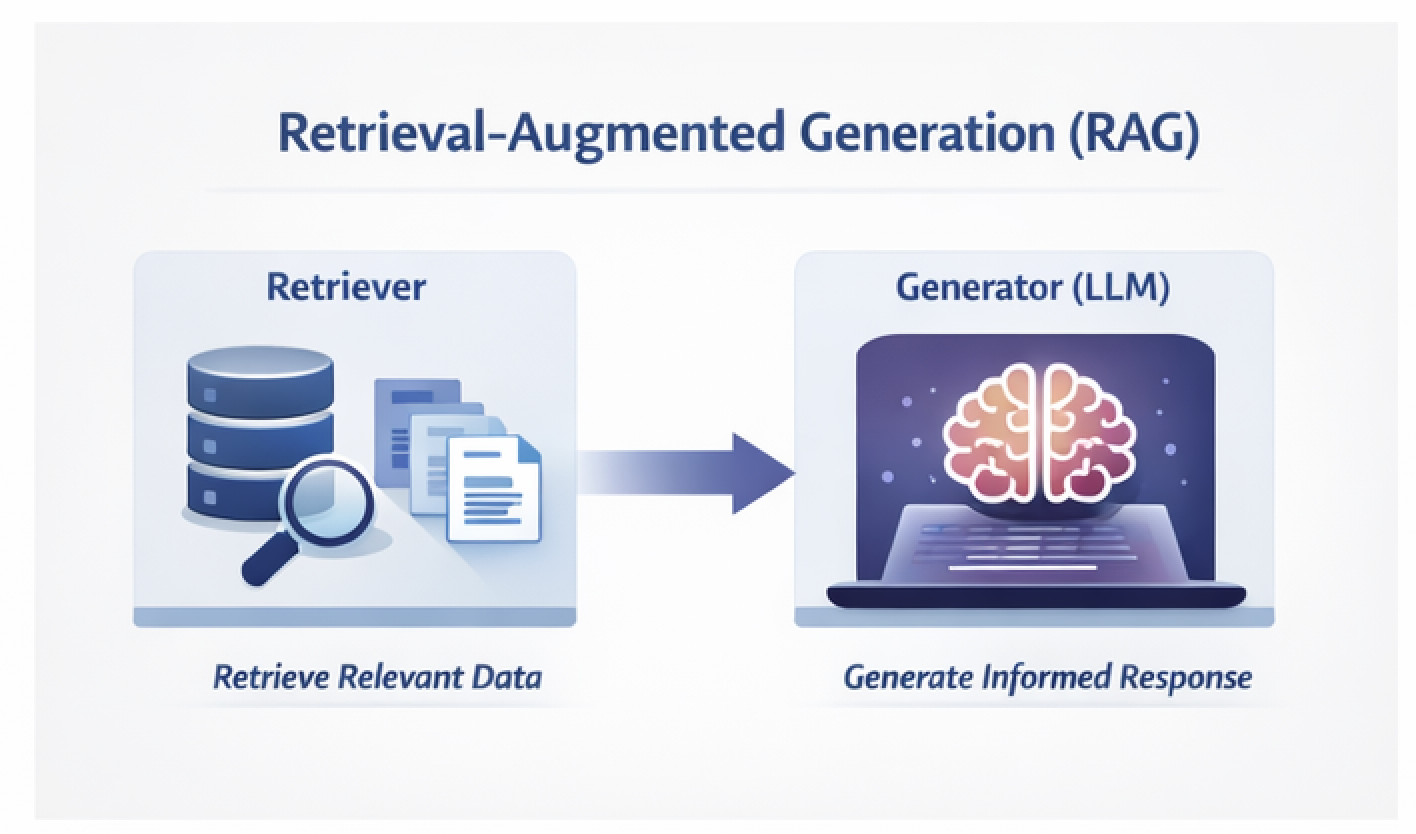
What Is Retrieval-Augmented Generation?
Retrieval-Augmented Generation combines two distinct components:
- Retriever – Fetches relevant information from an external knowledge source
- Generator (LLM) – Produces responses grounded in the retrieved context
Instead of relying solely on parametric memory from models developed by OpenAI or Google DeepMind, RAG integrates external systems such as:
- Vector databases
- Enterprise document repositories
- Knowledge management systems
- Structured and semi-structured data stores
The model retrieves what it needs at runtime rather than attempting to encode all knowledge into its weights.
Why Pure LLM Architectures Break Down
As teams have deployed AI systems, several limitations have become evident.
1. Hallucinations
LLMs generate plausible responses even when lacking factual grounding.
2. Knowledge Freshness
Model training data is static. Enterprises operate on dynamic, continuously evolving data.
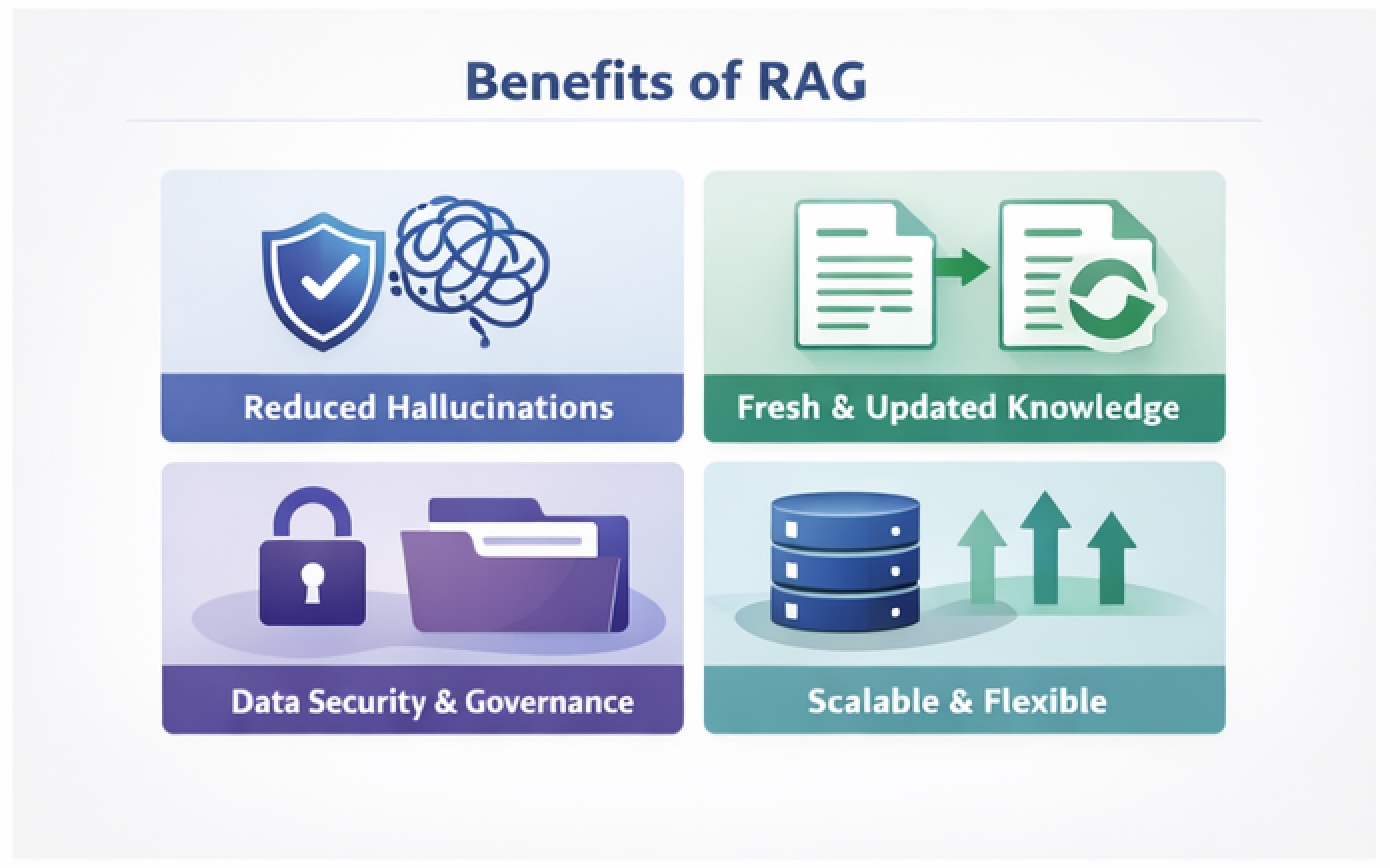
3. Data Governance
Sensitive enterprise information cannot simply be embedded into model parameters.
4. Operational Cost
Fine-tuning large models for every domain-specific use case is slow and expensive.
RAG addresses these challenges through architectural separation rather than brute-force scaling.
The Core RAG Pipeline
At a systems level, the architecture looks like this:
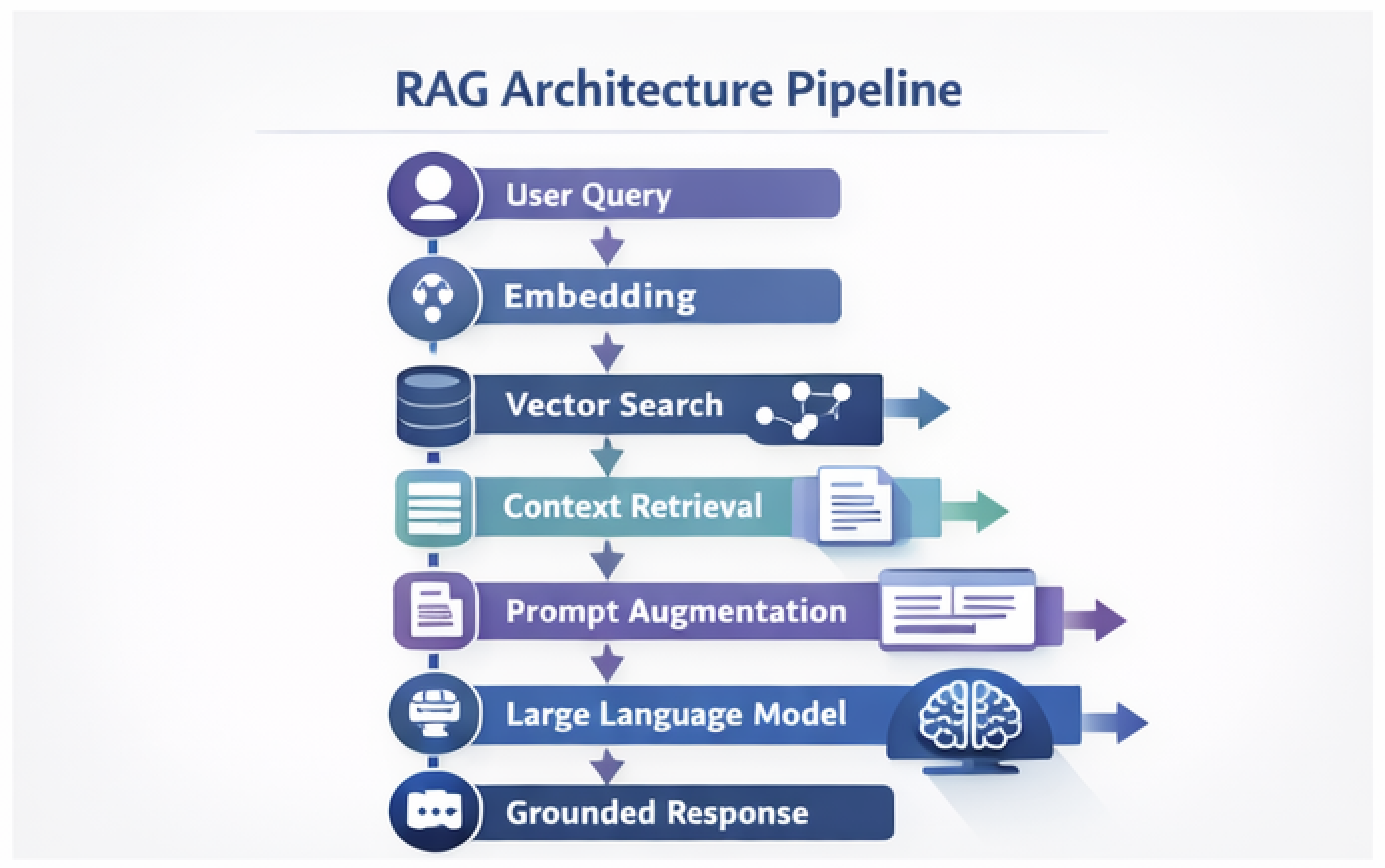
Let us examine each step.
Step 1: Embedding
The user query is transformed into a dense vector representation using an embedding model.
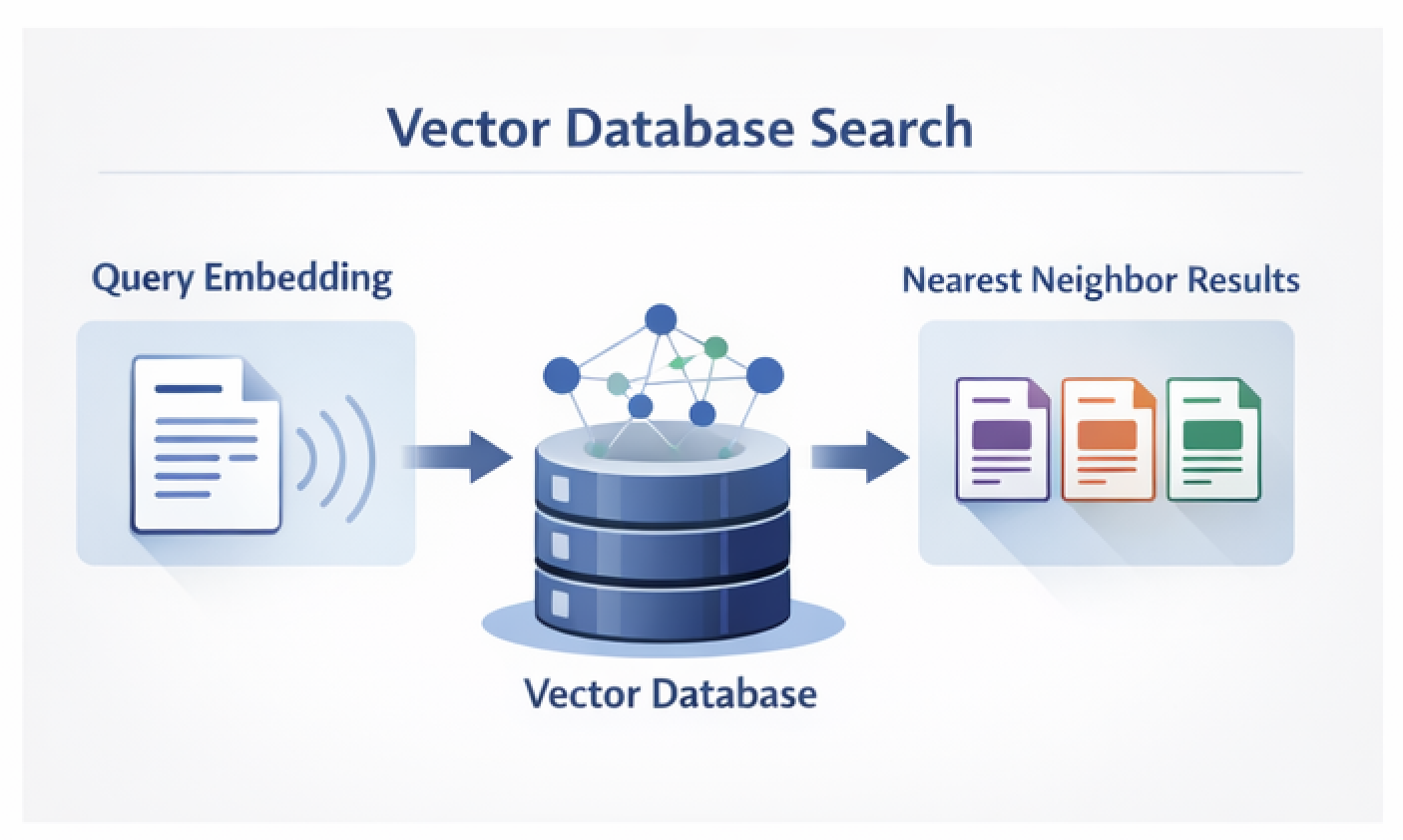
Step 2: Retrieval
A similarity search is performed against a vector index. Common platforms include:
- Pinecone
- Weaviate
- Milvus
Step 3: Context Injection
The most relevant document chunks are appended to the prompt.
Step 4: Generation
The LLM produces a response grounded in the supplied context.
This architecture introduces deterministic knowledge boundaries. The model answers based on retrieved evidence.
Why RAG Has Become the Default Pattern
Architectural Alignment
RAG cleanly separates:
- Storage layer
- Retrieval layer
- Generation layer
This mirrors established distributed systems principles such as separation of concerns, scalability, and observability.
Improved Observability
With RAG, engineers can inspect:
- Retrieved documents
- Similarity scores
- Prompt construction
- Output grounding
Pure LLM systems are opaque. RAG systems are inspectable.
Reduced Hallucination Risk
While not eliminating hallucinations entirely, RAG shifts the model’s task from inventing plausible text to summarizing retrieved context.
Scalable Knowledge Management
As data grows, teams can:
- Add documents
- Re-embed content
- Update vector indexes
No full model retraining required.
When RAG May Not Be Necessary
RAG is not universal. It may be unnecessary when:
- Tasks are purely creative
- Knowledge requirements are static and small
- Ultra-low latency is critical
- Retrieval quality cannot be reliably determined
Like any architecture pattern, it must be applied intentionally.
Best Practices
Teams building serious RAG systems adopt several practices:
- Semantic document chunking
- Metadata filtering
- Hybrid search (keyword plus vector search)
- Re-ranking layers
- Intelligent context window management
RAG has evolved from a conceptual pattern into a performance engineering discipline.
A Broader Architectural Shift
Historically, software systems converge on dominant patterns:
- REST for web services
- ETL pipelines for data engineering
- Microservices for distributed systems
For AI systems, RAG has emerged as that default starting point.
It introduces structure, governance, and scalability into AI deployments. It bridges classical engineering principles with modern generative models.
Closing Thoughts
RAG does not replace engineering discipline. It reinforces it.
As AI systems mature, Retrieval-Augmented Generation, or patterns derived from it, are likely to form the backbone of enterprise AI architecture.
The architecture matters more than the prompt.